Introducing Leaf Computing
• Updated
This is an adaptation of my presentation at API Conference in London, UK on April 27, 2023, Apidays Helsinki on June 4, 2023 (video recording), and Nordic APIs Platform Summit on October 18, 2023.
More information can be found at LeafComputing.net.

Today I’m going to share some ideas publicly for the first time that I have been thinking about for a decade from my work on Fitbit smart watches, Spotify Connect devices, and e-bikes.
I call it leaf computing. It’s what I think comes next, after cloud computing. It’s both a complement and a replacement. It’s what I think is necessary—both technically and politically—to rebalance the power of technology back to empowering users first. To explain this, I will share a few stories.


In 2015, I spent a week hiking in Banff, Canada. It’s one of the most stunning national parks I have ever been to. Banff is filled with tall mountains, deep valleys, and wide glaciers.
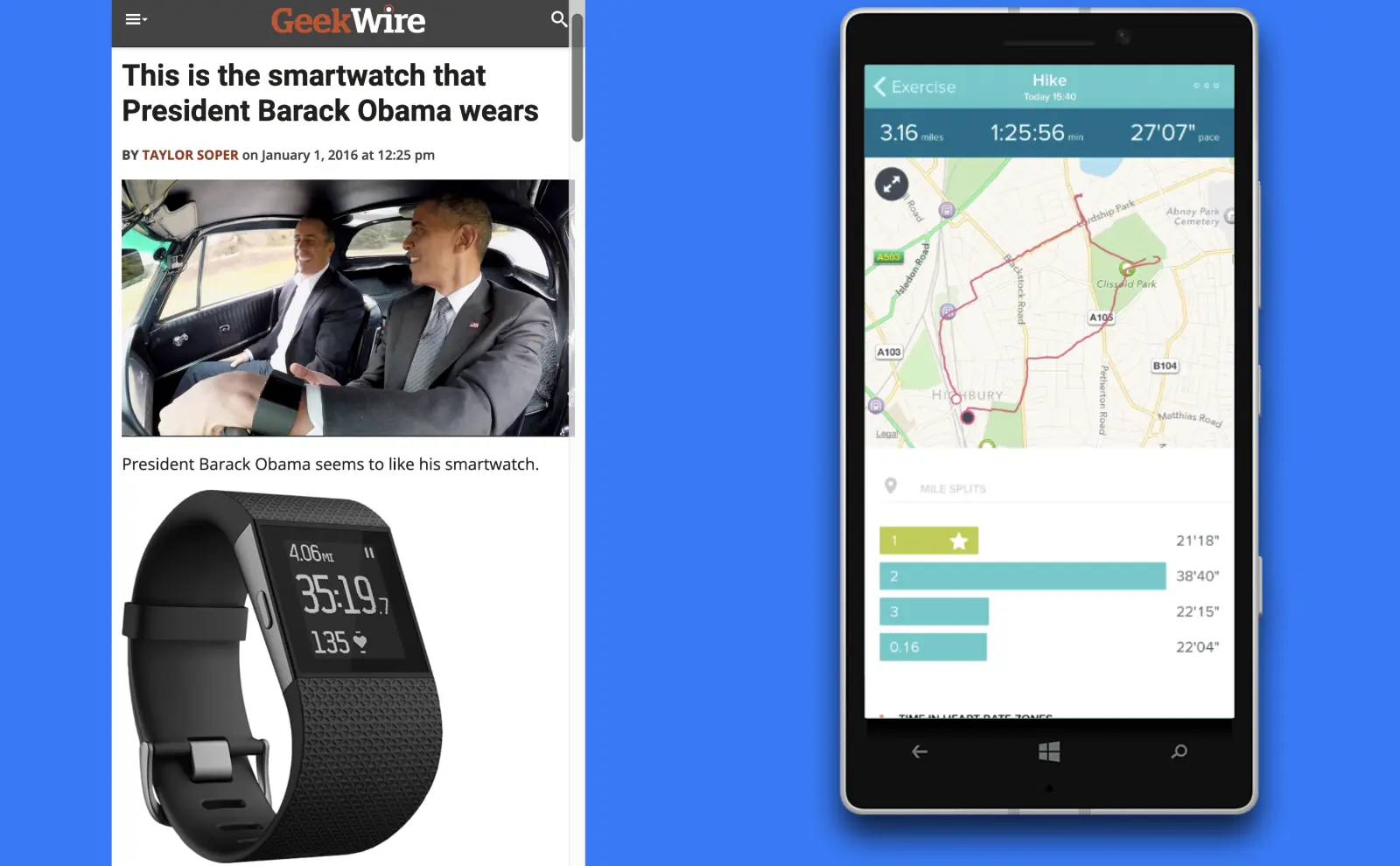
Along with my usual hiking gear, I had a Fitbit fitness watch and my smartphone. My Fitbit smart watch recorded my GPS location, steps, heart rate, elevation change, and all that great data from my wrist. At the end of the day, I wanted to view my data on my phone. Only here was a little problem.
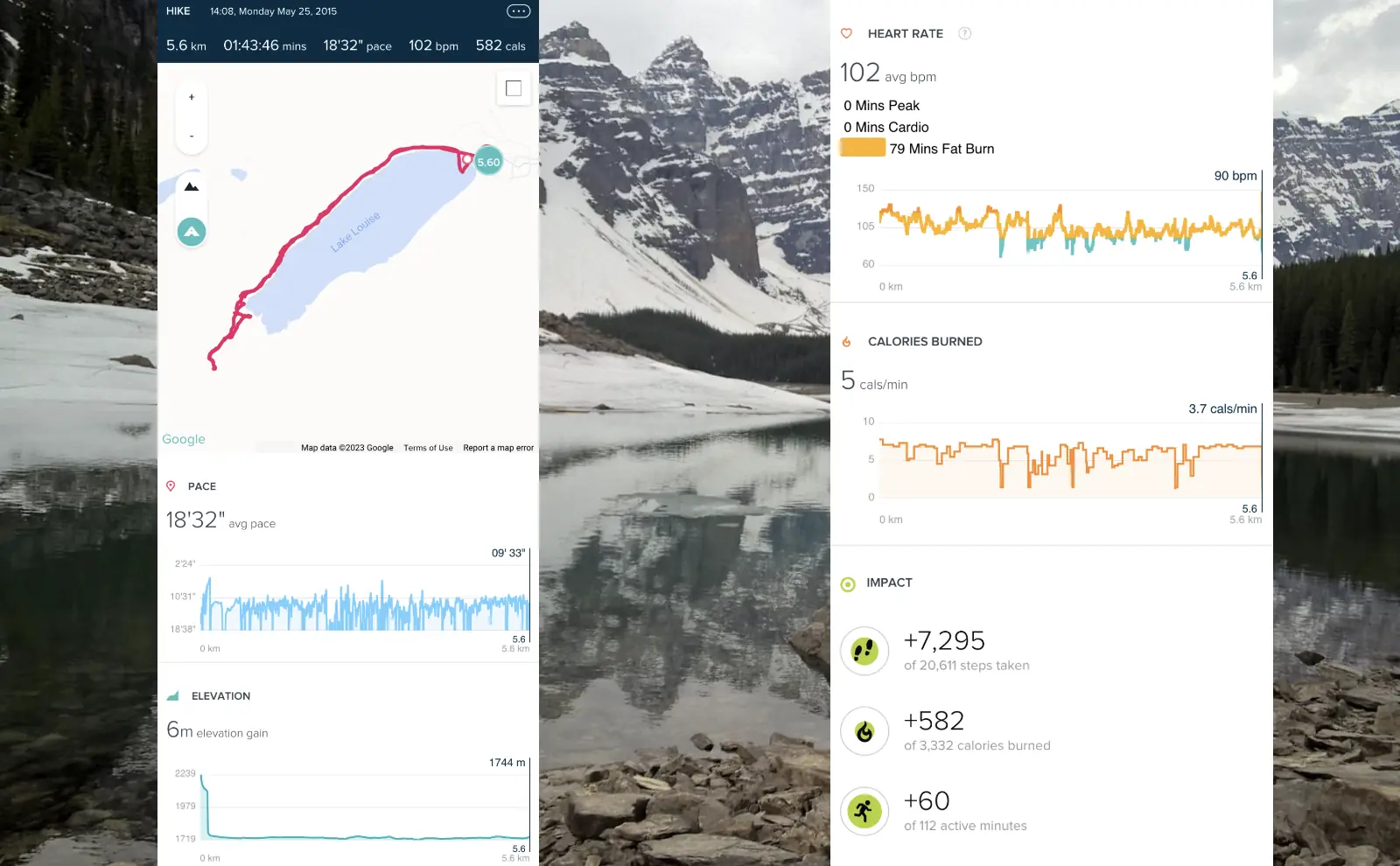
Cell coverage was limited to the main roads and even then, it was quite slow 3G. Again, it was 2015. It was too slow to upload all of that data from my smartwatch to Fitbit’s servers. While the upload made steady, incremental progress, Fitbit’s servers would cut off the connection after 2 minutes. I tried and retried, but it kept failing after 2 minutes.

Now, I was working as a software engineer on Fitbit’s API at the time. I had a hunch about the reason: our reverse-proxy server timeout was set to 120 seconds. We hadn’t anticipated the possibility of a half MB of data taking longer than 2 minutes to upload. Keep in mind, that’s slower than a 56K modem.
My smart watch and my smart phone were not so smart when in the wilderness. I had some of the capabilities, like collecting the data and seeing some of the data on the watch, but I couldn’t get the full experience on my phone because of my intermittent Internet connectivity.
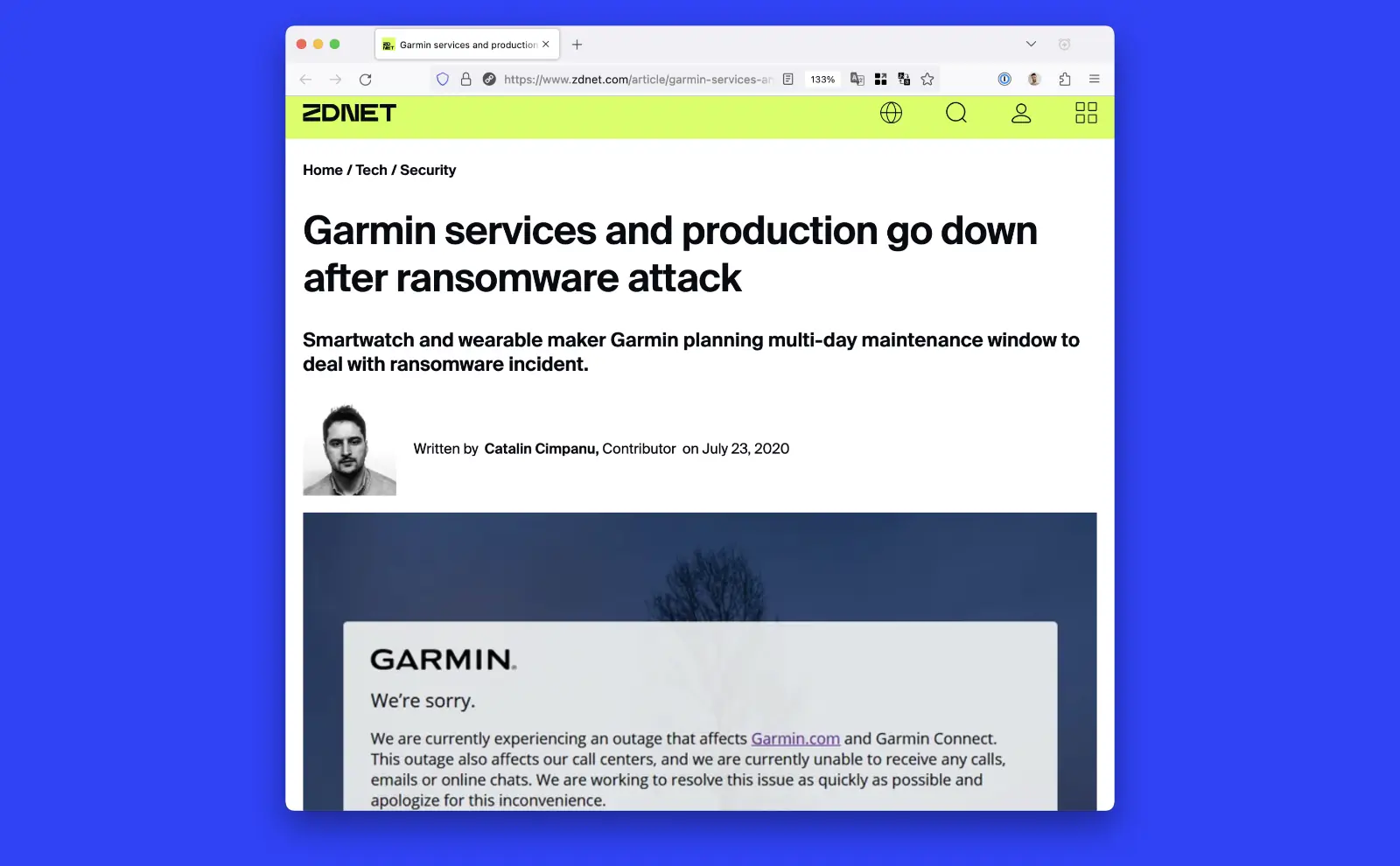
This connectivity problem was on the client side, but problems can exist on the server side as well. That happened to Fitbit’s competitor, Garmin, in July 2020.
A hacker gained access to Garmin’s internal computer systems. (source) It held the company hostage for 5 days demanding $10M. It’s unknown if Garmin paid the ransom, but for 2 days it went completely offline. Most Garmin smart watches just didn’t sync for 2 days.
But server outages are not caused exclusively by hackers.
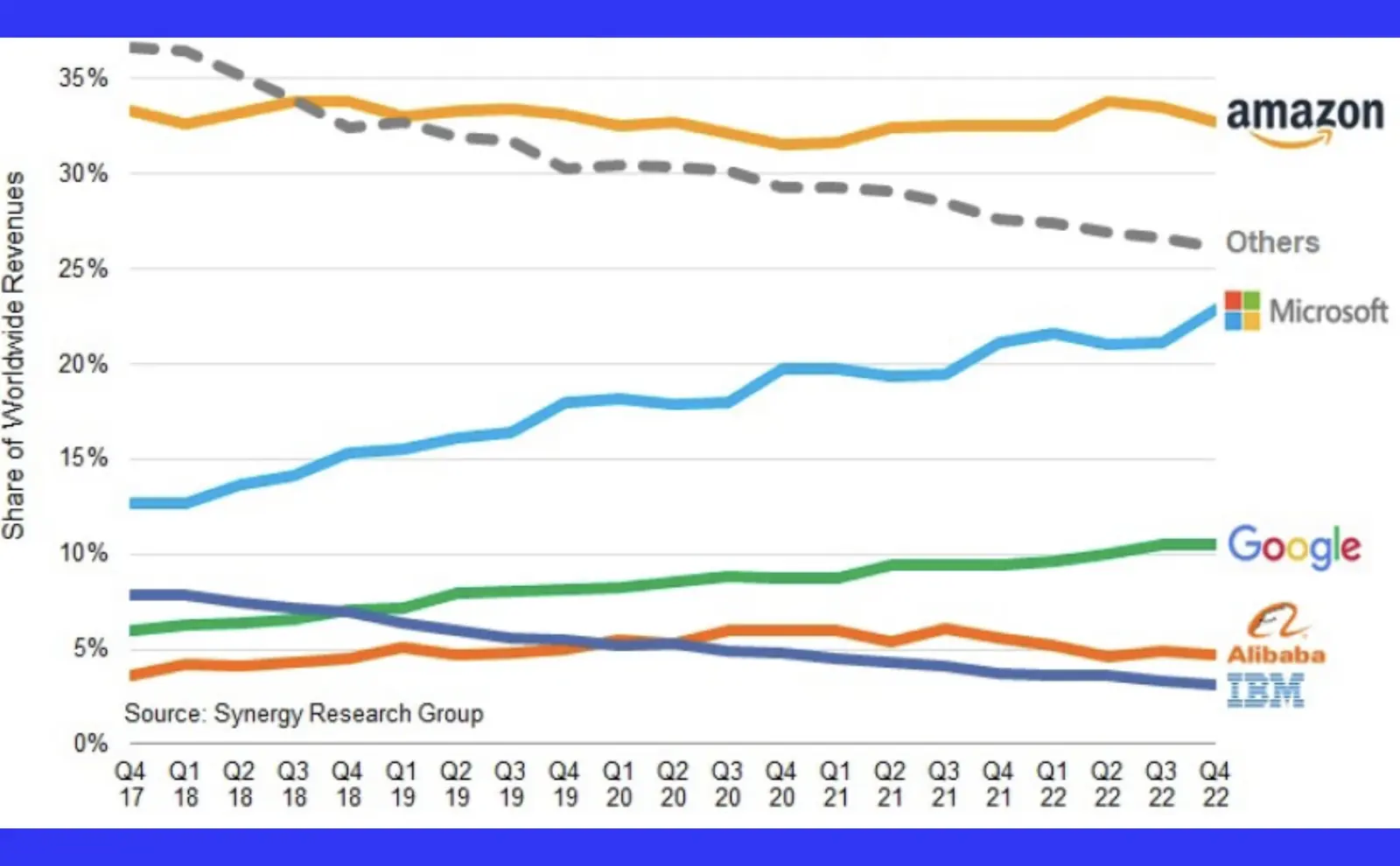
AWS is the most popular cloud infrastructure provider in the world with 33% marketshare. That means a significant portion of what you do online everyday touches AWS’s data centers. What happens when it goes down? We don’t have to imagine, we get a reminder every few years of what happens.
The US-east-1 region is AWS’s most popular datacenter. It’s the default region for many of AWS’s services and typically the first region to get new features.
In December 2021, AWS US-east-1 region went down 3 separate times, the worst incident for about 7 hours. (source) Popular websites like IMDb, Riot Games, apps like Slack and Asana were just down. But websites and apps that depend on the Web going down is kinda expected in such an outage.
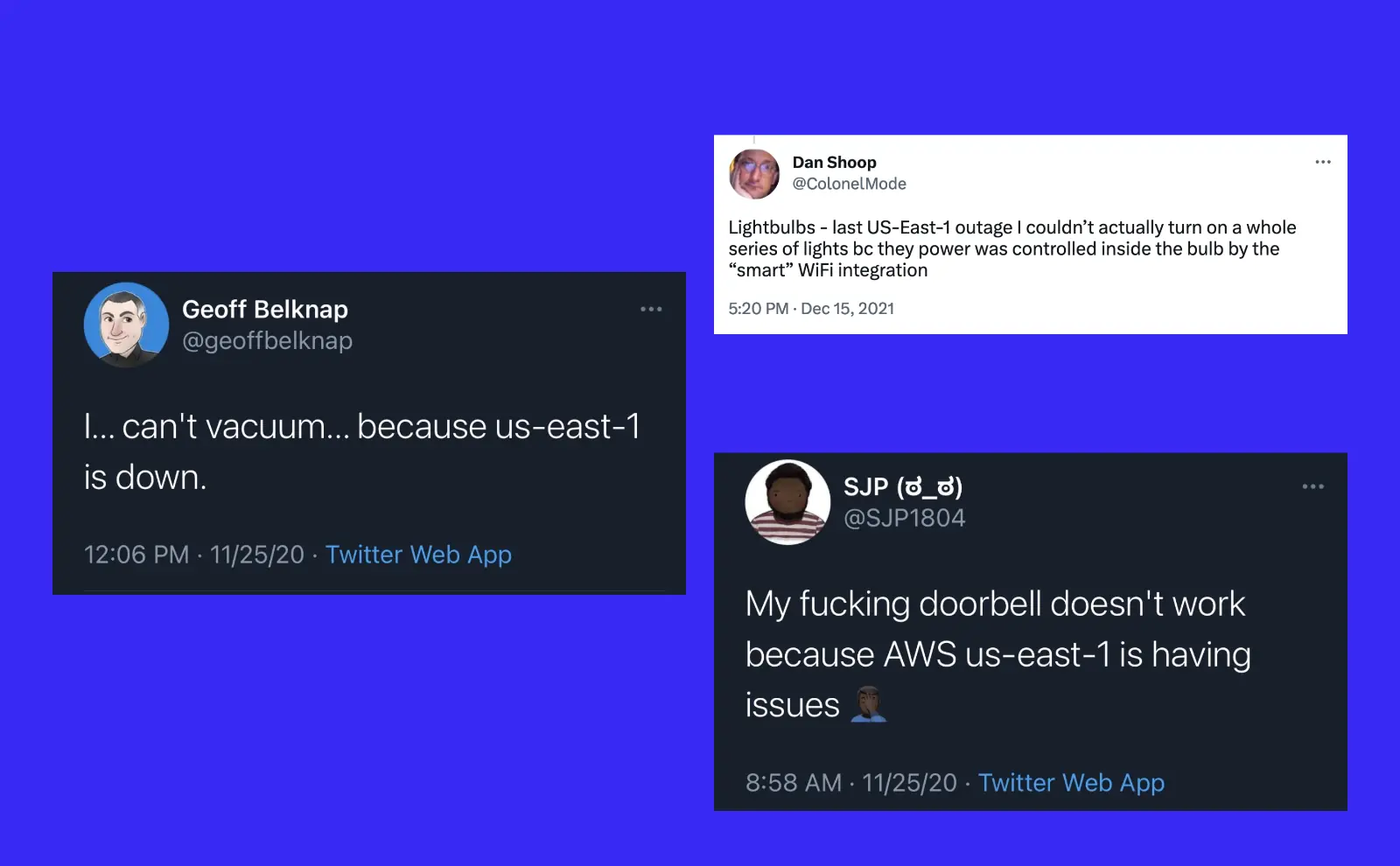
More interesting to me however is that floors went unvacuumed during this time. Roomba robotic vacuums stopped working. Doors went unanswered because Amazon Ring doorbells stopped working. People were left in the dark because some smart light brands couldn’t turn on/off.
At least they eventually started working again.
I’ve mentioned hackers taking servers offline and cloud providers accidentally taking themselves offline, but another way servers go offline is when you stop paying for them because your company goes out of business.
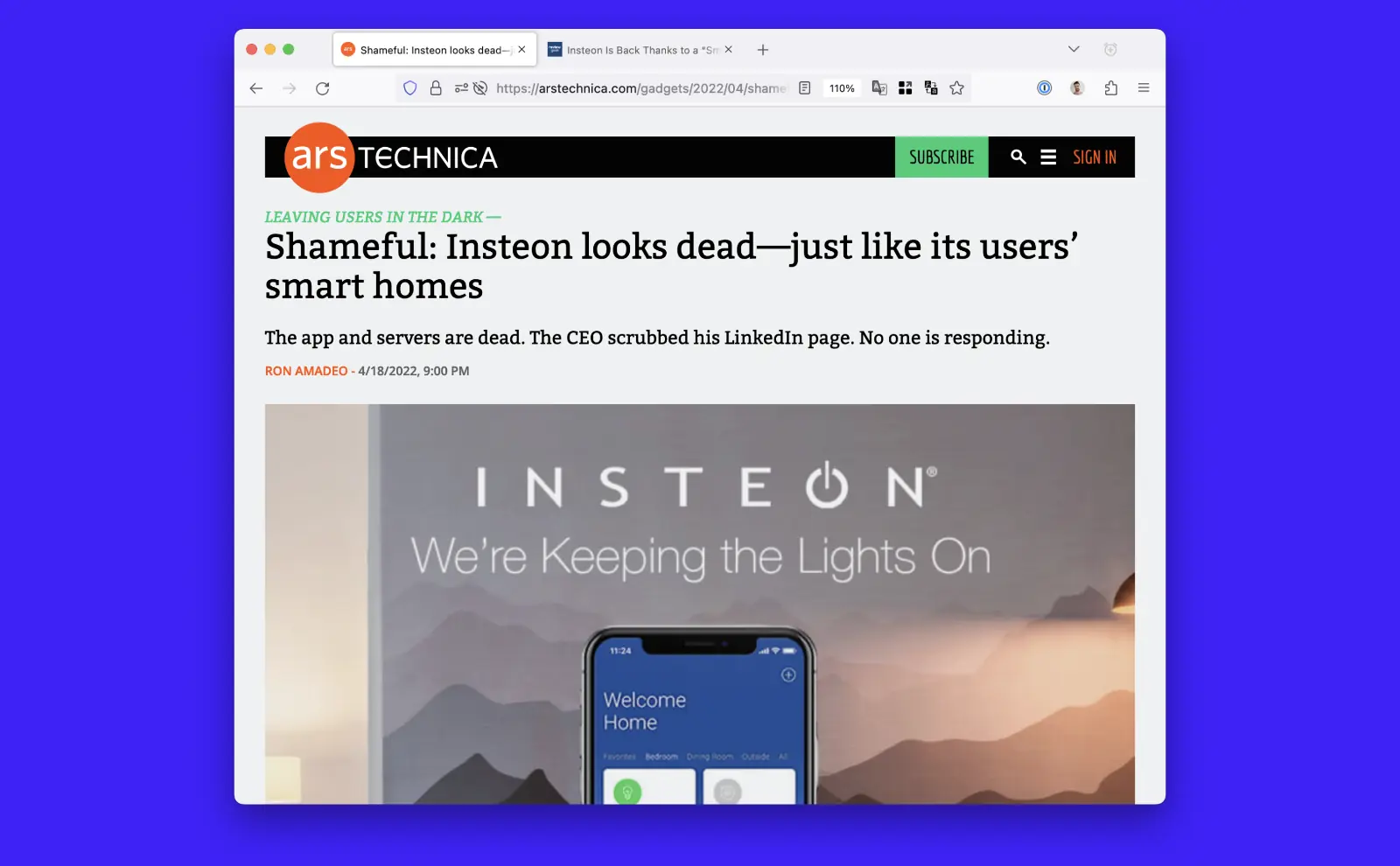
In 2022, smart home company Insteon abruptly ceased business operations one weekend. Its customers’ home automations for lights, appliances, door locks, and such just stopped working without warning. Emails to customer support went unanswered. The CEO scrubbed his LinkedIn profile. The company just vanished and millions of dollars in smart home electronics became e-waste.
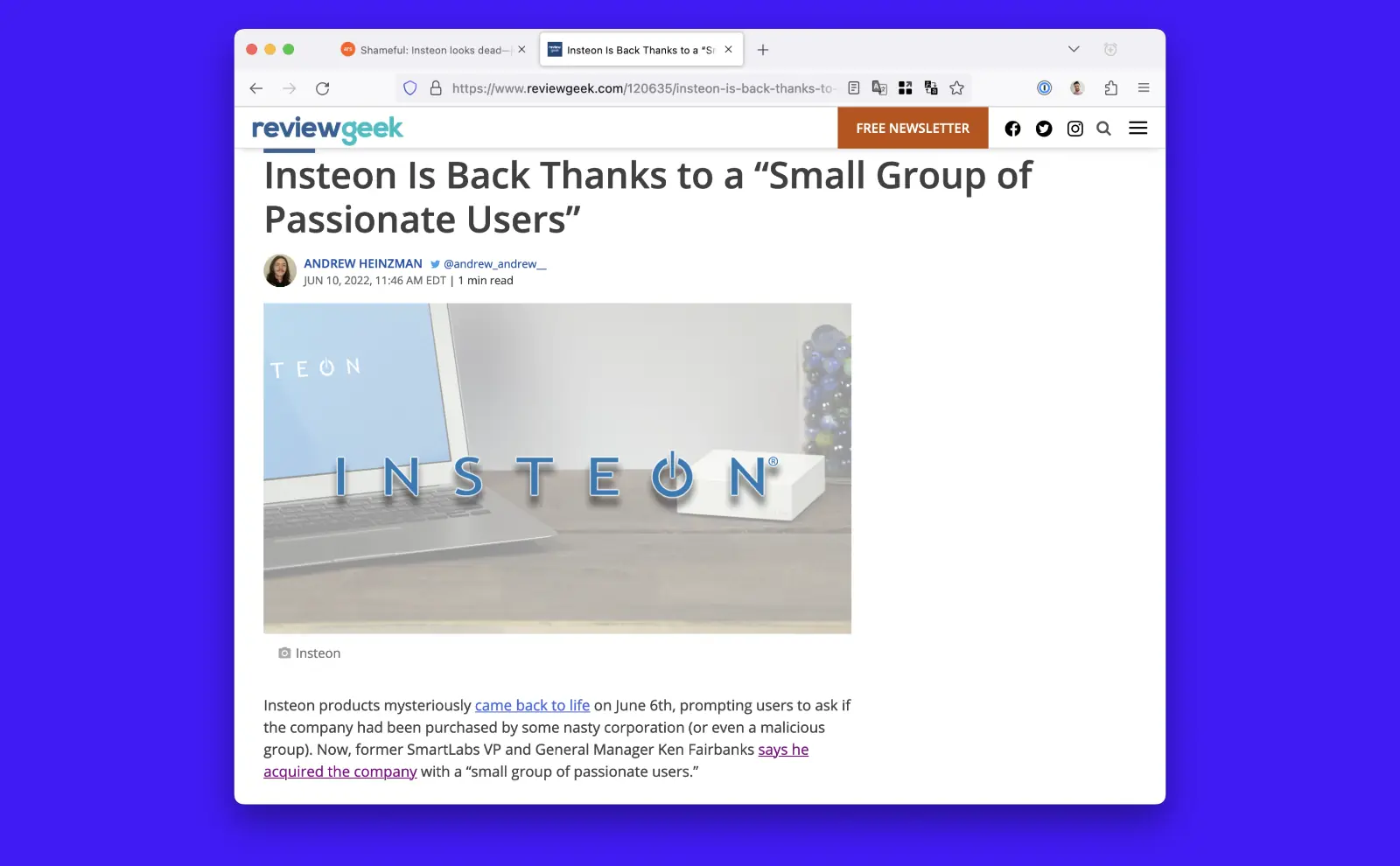
Thankfully, some of its customers connected with each other on Reddit, started reverse engineering protocols, building open source software, and eventually got together to purchase the dead company’s assets. It was a triumph of the human spirit or at least rich techies with some free time.

The point of this story is that so many of the physical devices we now own require not just electricity, but a constant Internet connection. They’re right beside you physically and yet a world apart because they can’t connect to a server on another continent.

Ok, final set of stories.
There is an Internet meme: “There is no cloud. It’s just someone else’s computer.” The point of this meme is not to disparage the genuine innovation of seemingly boundless computational capacity available instantly with an API request and a credit card. The point of this meme is to remind people that when you put your data into the cloud, you are entrusting other people to take care of it. Unfortunately, the companies and the people who work at those companies do not always do the best job at that.
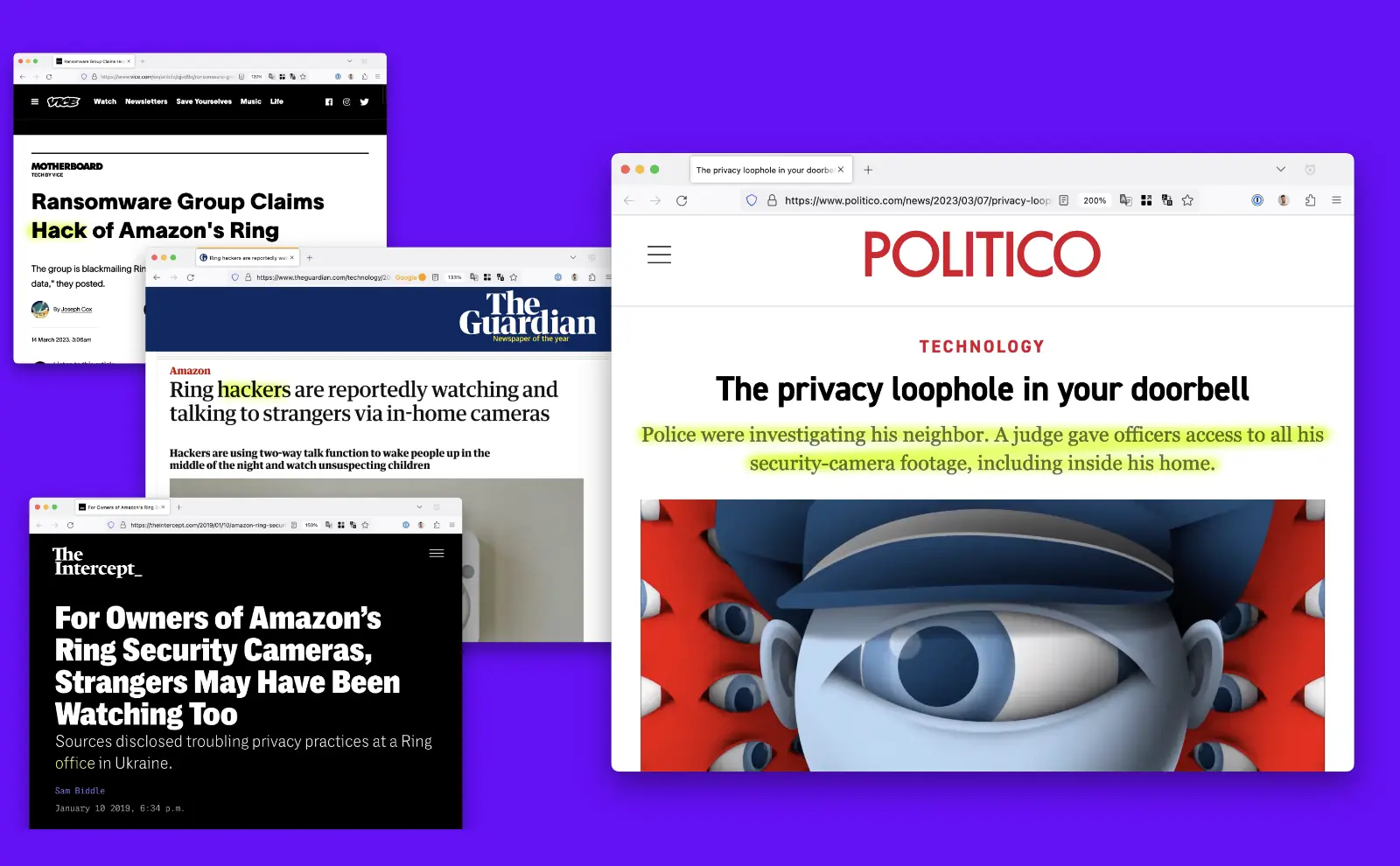
In 2021, Security camera company Verkada had thousands of customers: big corporations like Tesla, hospitals in 3 US states, several US airports, and even Sandy Hook Elementary School. Its products not only provided video surveillance, but also facial recognition of individuals in the video. The data was extremely sensitive.
One day, Verkada’s customers got an email informing them that hackers had gotten access to a so called “super admin” employee account. This account allowed the hackers to see all of the live video feeds and archived video of all Verkada’s customers. This was a huge breach.
The most interesting admission by Verkada was not that a security breach had occurred, but that there was an employee account with this level of access to its customers data in the first place that could be hacked.
Just a year earlier, a whistleblower at the company went public with accusations that Verkada employees were abusing the level of access they had to customer data. They alleged some employees were taking screenshots of women in the security feeds and sharing them internally. The company denied this, but hackers confirmed this capability still very much existed a year later.
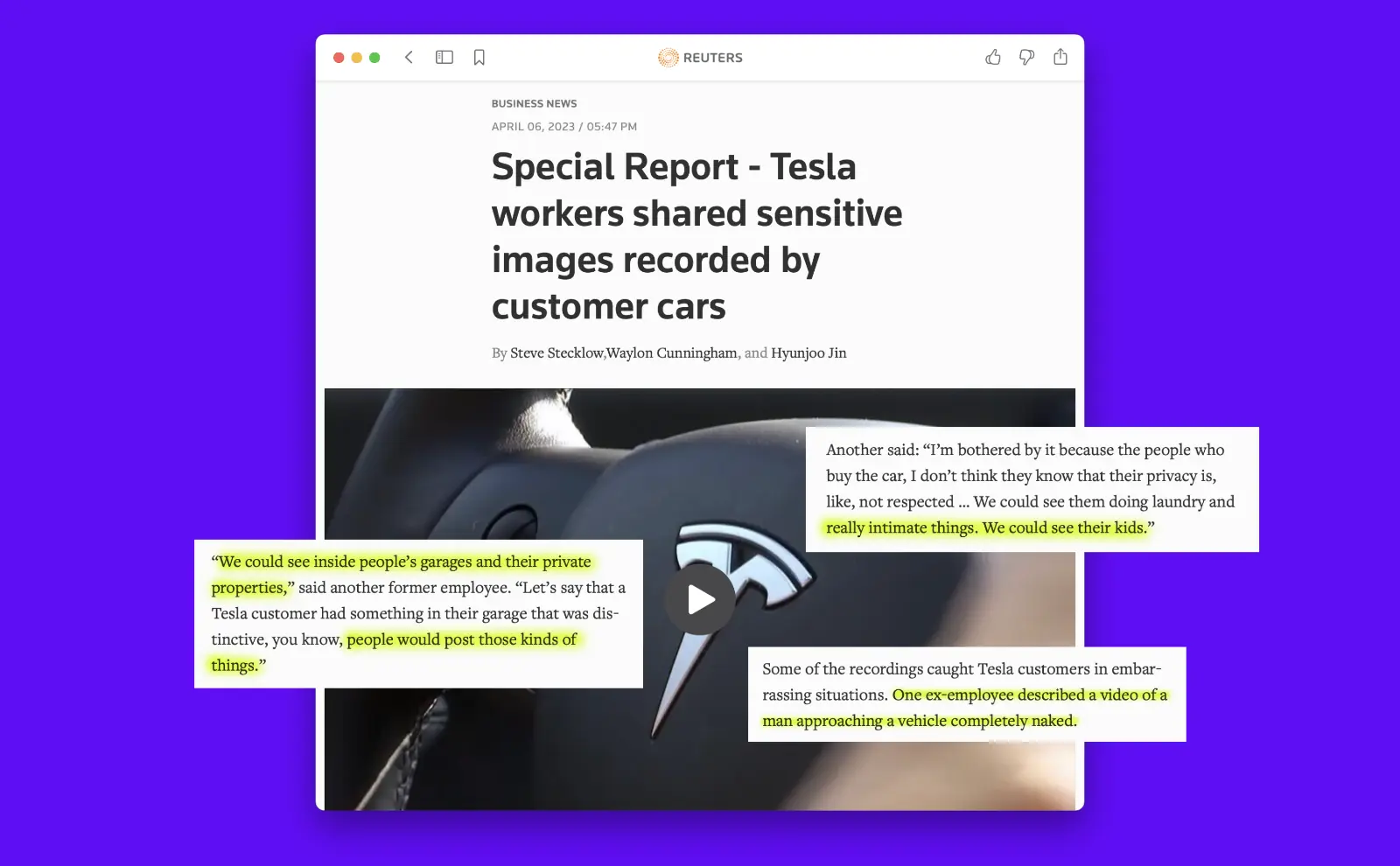
Earlier this month, Tesla went from being a victim of Verkada to being accused of doing the same thing. Tesla cars are equipped with a bunch of cameras used for its autonomous driving and safety features. 9 former employees now claim that for years, Tesla employees would share images and videos from customers’ cars in internal chat groups for amusement. One former employee said, “We could see them doing laundry and really intimate things. We could see their kids.” “We could see inside people’s garages and their private properties,” said another.
Ransomware Group Claims Hack of Amazon's Ring, Ring hackers are reportedly watching and talking to strangers via in-home cameras, For Owners of Amazon’s Ring Security Cameras, Strangers May Have Been Watching Too, The privacy loophole in your doorbell
Amazon Ring, however, truly wins the prize. It not only has extensive allegations of broad employee abuse of customer data and being hacked multiple times, it also has admitted to giving police customer data without user consent and sometimes without a warrant. In one case, Ring not only provided data requested, but additional video inside a customer’s home that was completely unrelated to the investigation.

People just wanted a way to easily unlock their door and accidentally helped create a dystopian surveillance state. It goes beyond invading the privacy of individuals to potentially harming all of society.

This is the present state of things. I’ve shared stories about Internet connected products not working well when the connection is bad, not working at all when servers are down, and actively working against their users when trust is misplaced. The central theme to these stories is the cloud architecture.

Does it have to be like this? Are we stuck with the Internet of Shit?
Let’s look at the smart watch example and try to figure out how we could achieve the same user experience in a way that:
- Works offline
- Doesn’t rely on trusting someone else to protect your data
- Doesn’t become e-waste if the servers go away
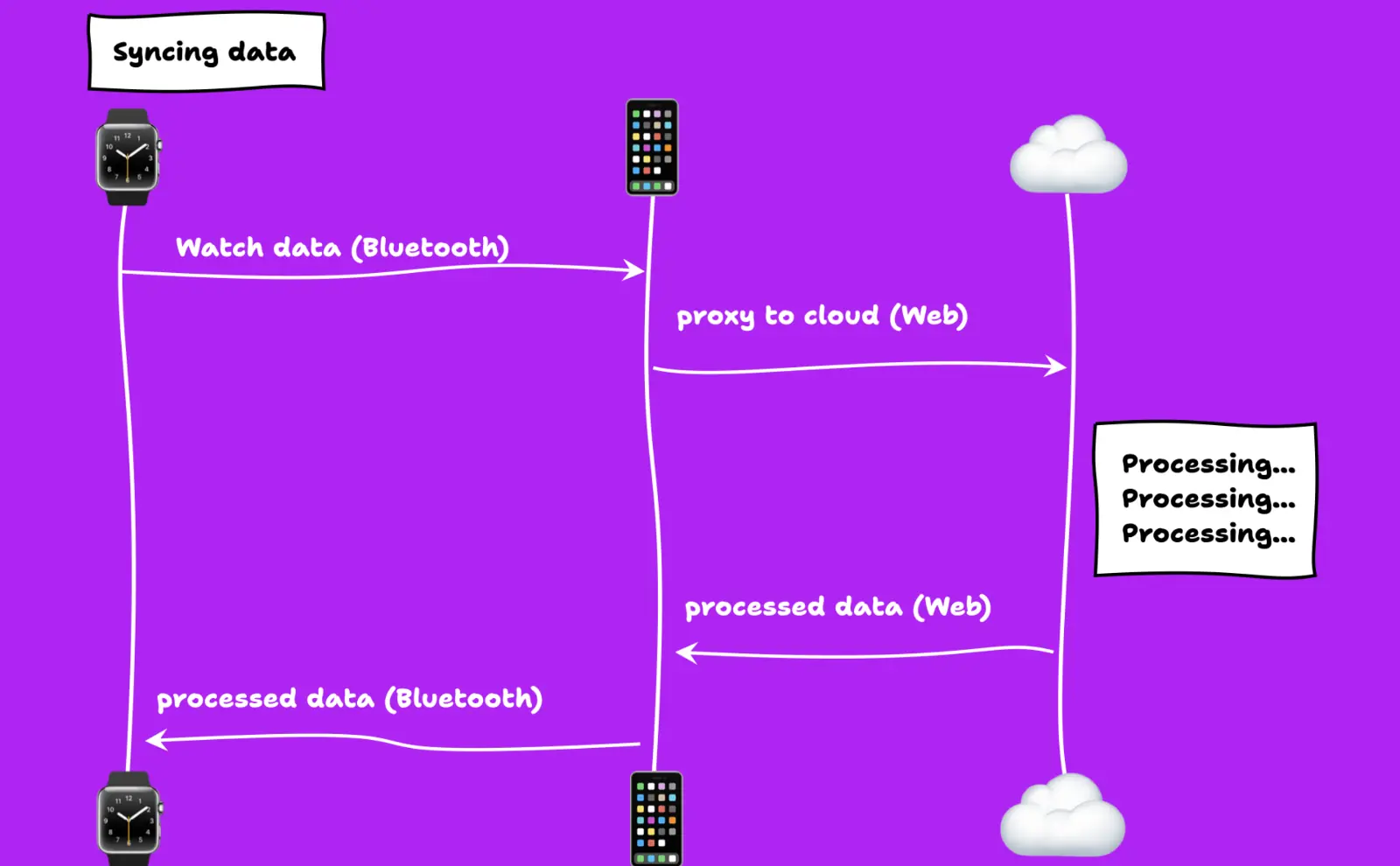
The typical present-day architecture looks like this:
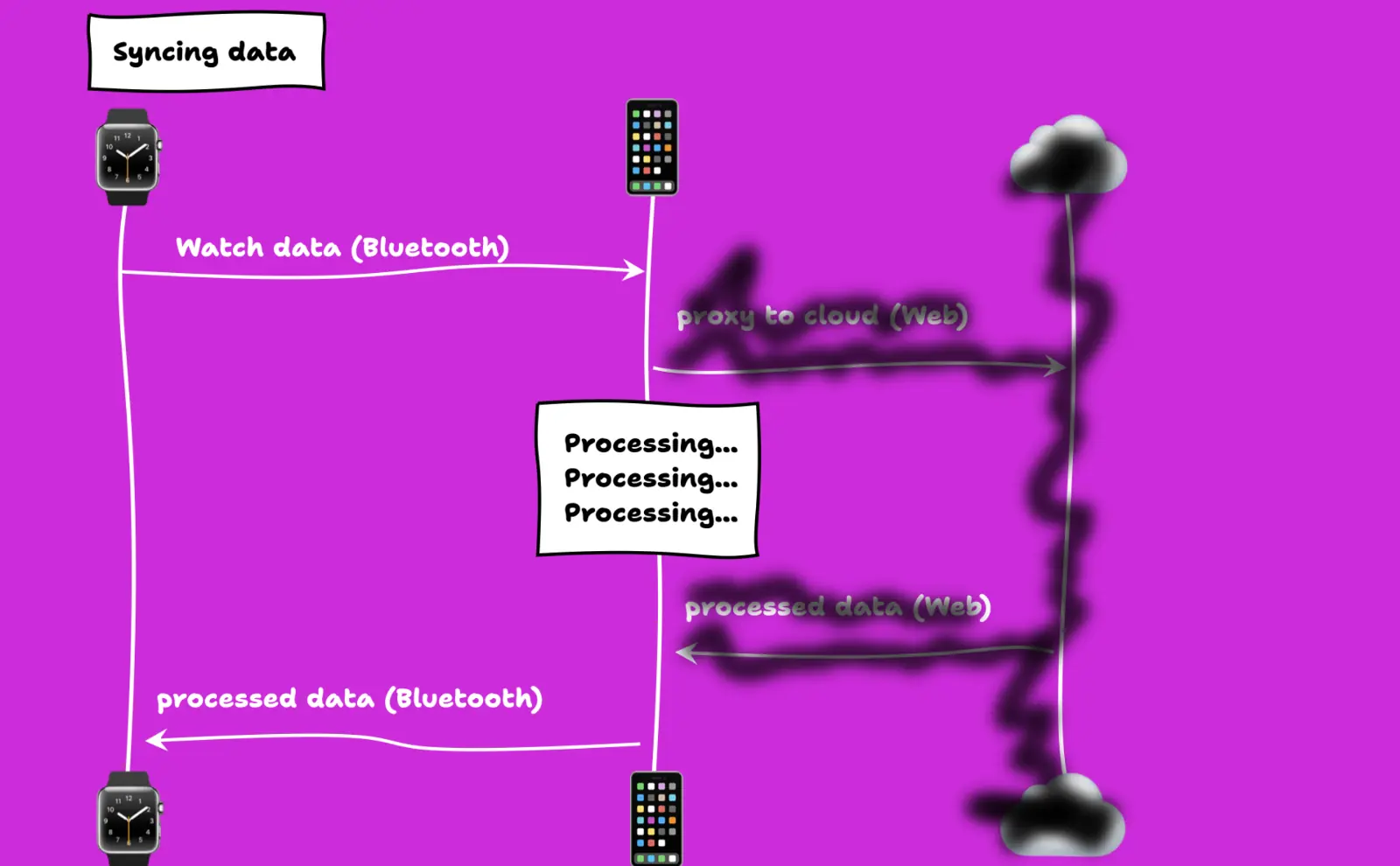
- The watch communicates with an app on the phone via Bluetooth to relay data from the watch to the server because the watch itself does not have a constant connection to the Internet. Wi-Fi is not always present and cell radios require paying for data and consume a lot of power from a tiny battery.
- The server does its processing of the watch data
- Sends it back to the phone, which
- Loads the state back to the watch.
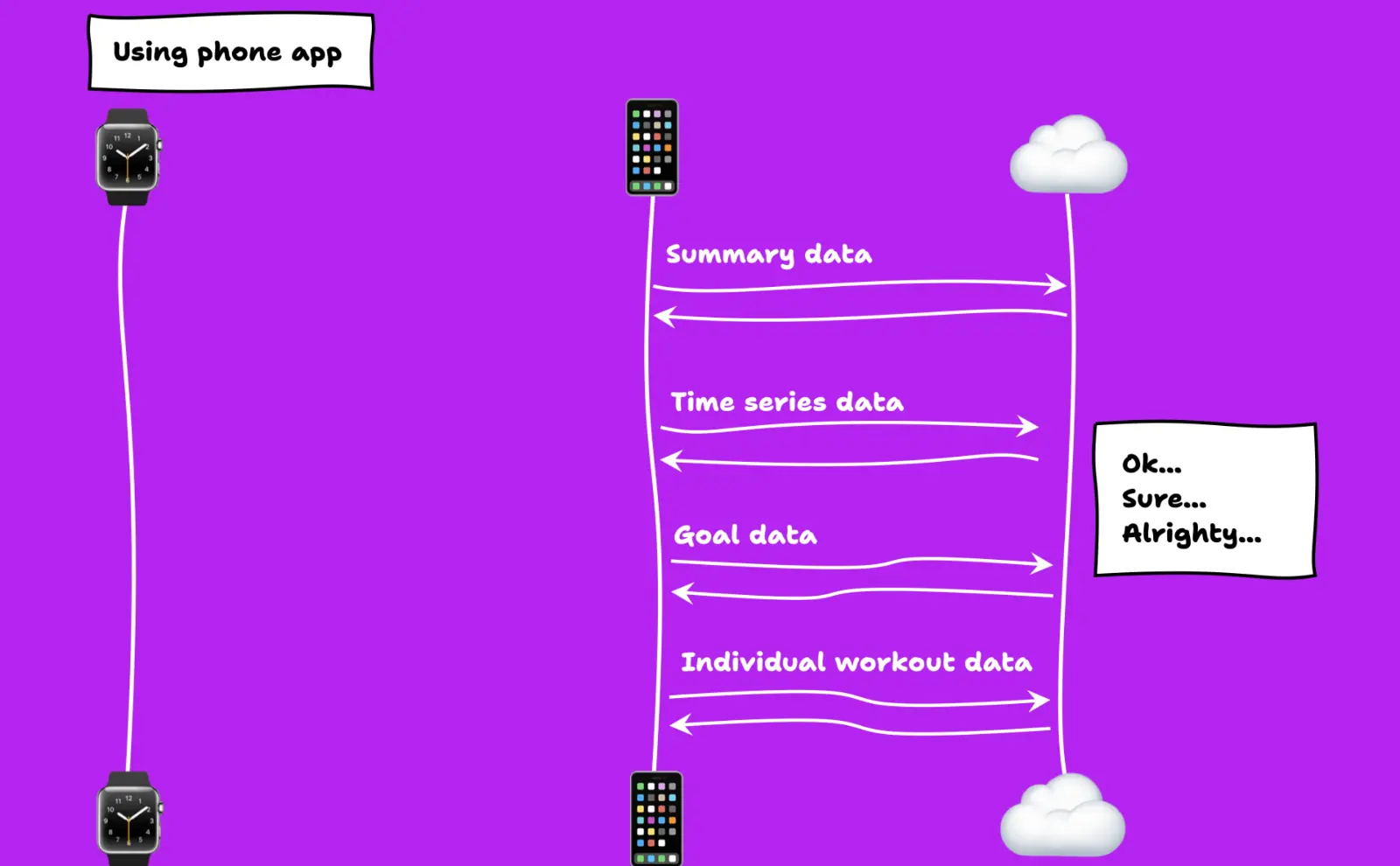
Then, when you use the app, the app makes a bunch of API requests to the server to retrieve the watch data but reformatted in a way that is easier to use as an app developer.
For example, the number of steps you take can be represented as a daily summary, a minute-level time series, and as progress against a daily step goal from a specific workout.
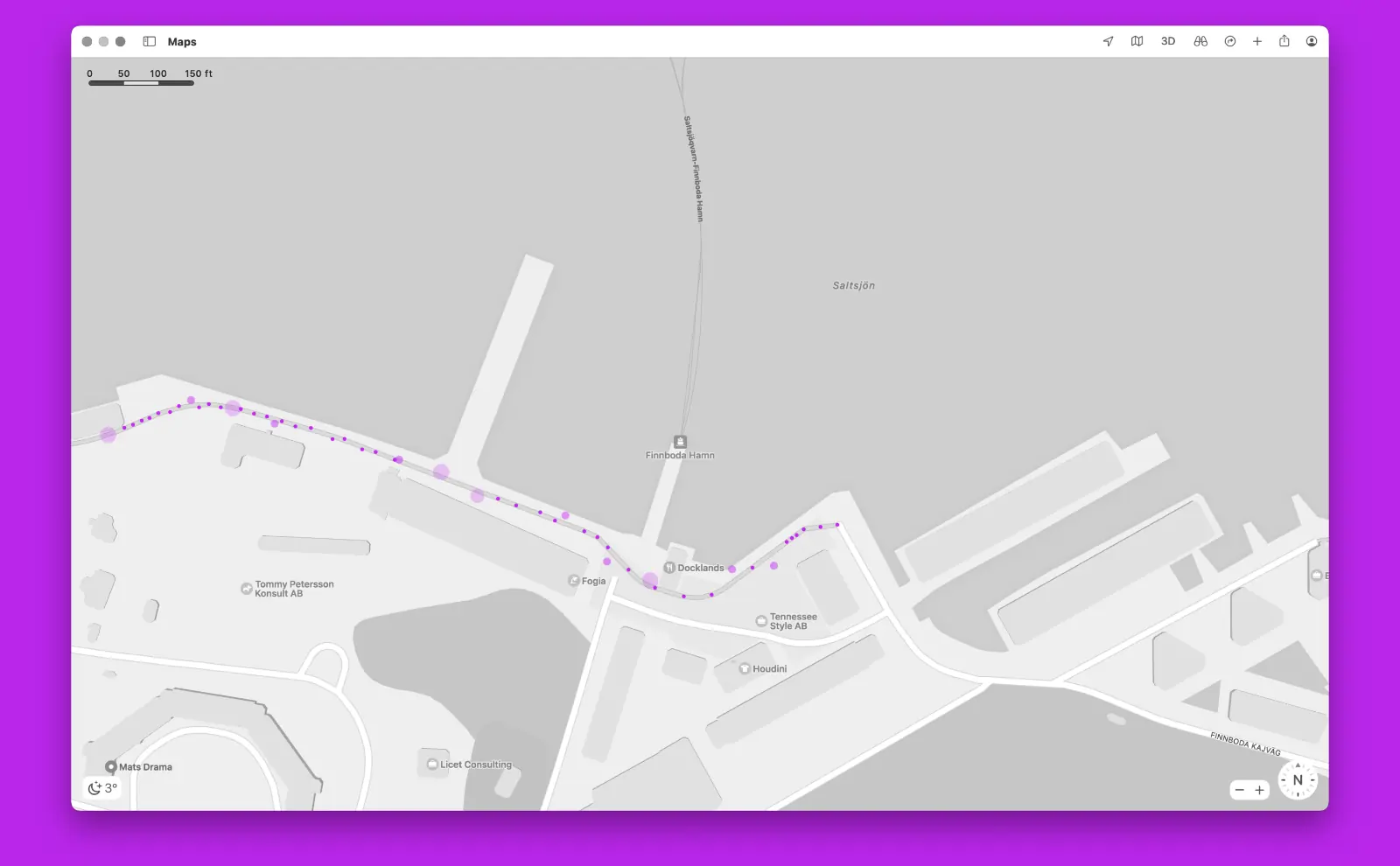
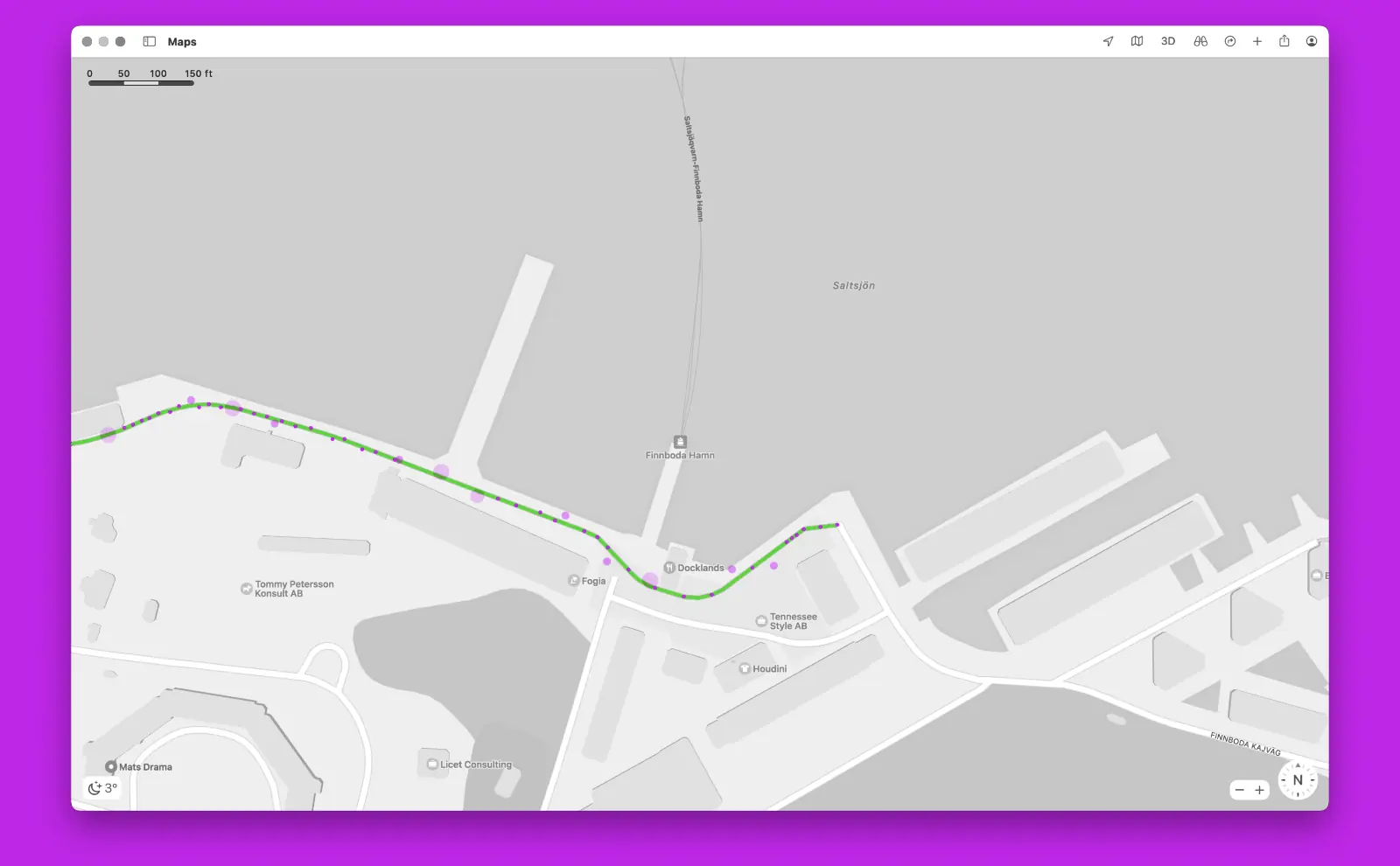
Another example is processing raw GPS data. If you’ve ever looked at raw GPS data, it looks like a scatter-plot of points with varying levels of calculated accuracy. It’s often not usable without some smoothing, which then requires recalculating distances to more closely match reality.

So how could we make this work offline? Could we just get rid of the server? What would it take to do that? It would mean moving the logic that exists on the server into the smart phone app. That seems quite reasonable to do in this use case.
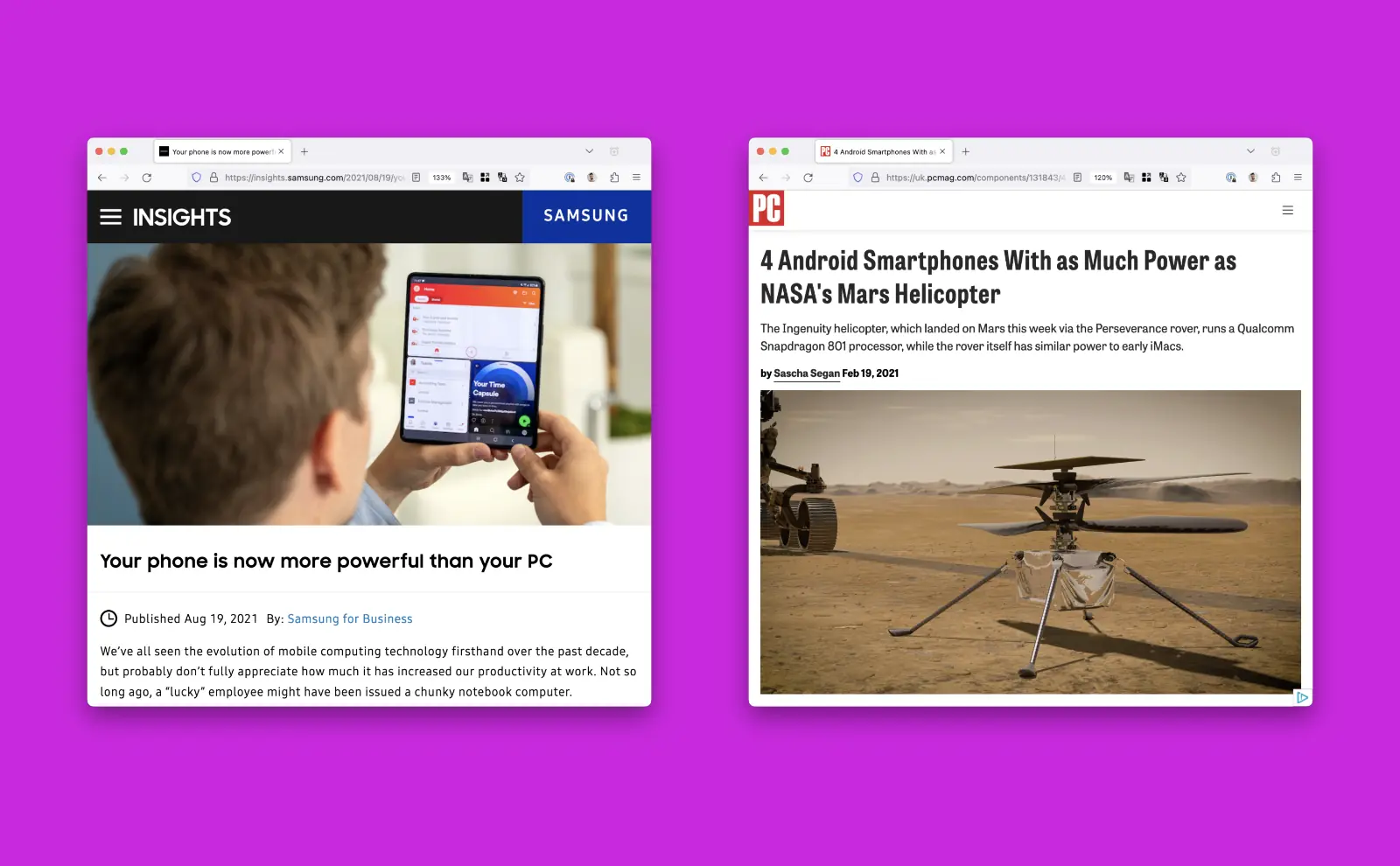
Your phone is now more powerful than your PC, 4 Android Smartphones With as Much Power as NASA's Mars Helicopter
Many people’s smart phones are now more powerful than the laptop computers they use, often with more RAM and storage space. There is no significant performance benefit of using a powerful server to do these types of computations.
Getting rid of the server not only shifts the computation expense to the phone, but also eliminates the data storage cost and responsibility of the provider. It saves businesses money and is more secure for the customer. Double win. The data stays on the phone and people can use the encrypted backup features of their phone to keep their data safe.
This proposal is not unrealistic. This is, in fact, exactly the architecture Apple chose when it introduced its own smart watch, the Apple Watch.

The Apple Watch’s cloudless architecture is inherently:
- More secure because the data stays on devices within your control
- More resilient because it’s not dependent on network connectivity to function
- More ecological because it will keep on ticking if Apple stops making the Watch tomorrow
The problem is that other smart watch makers have not chosen to imitate the cloudless architecture of the Apple Watch and the problem is not limited to smart watches.
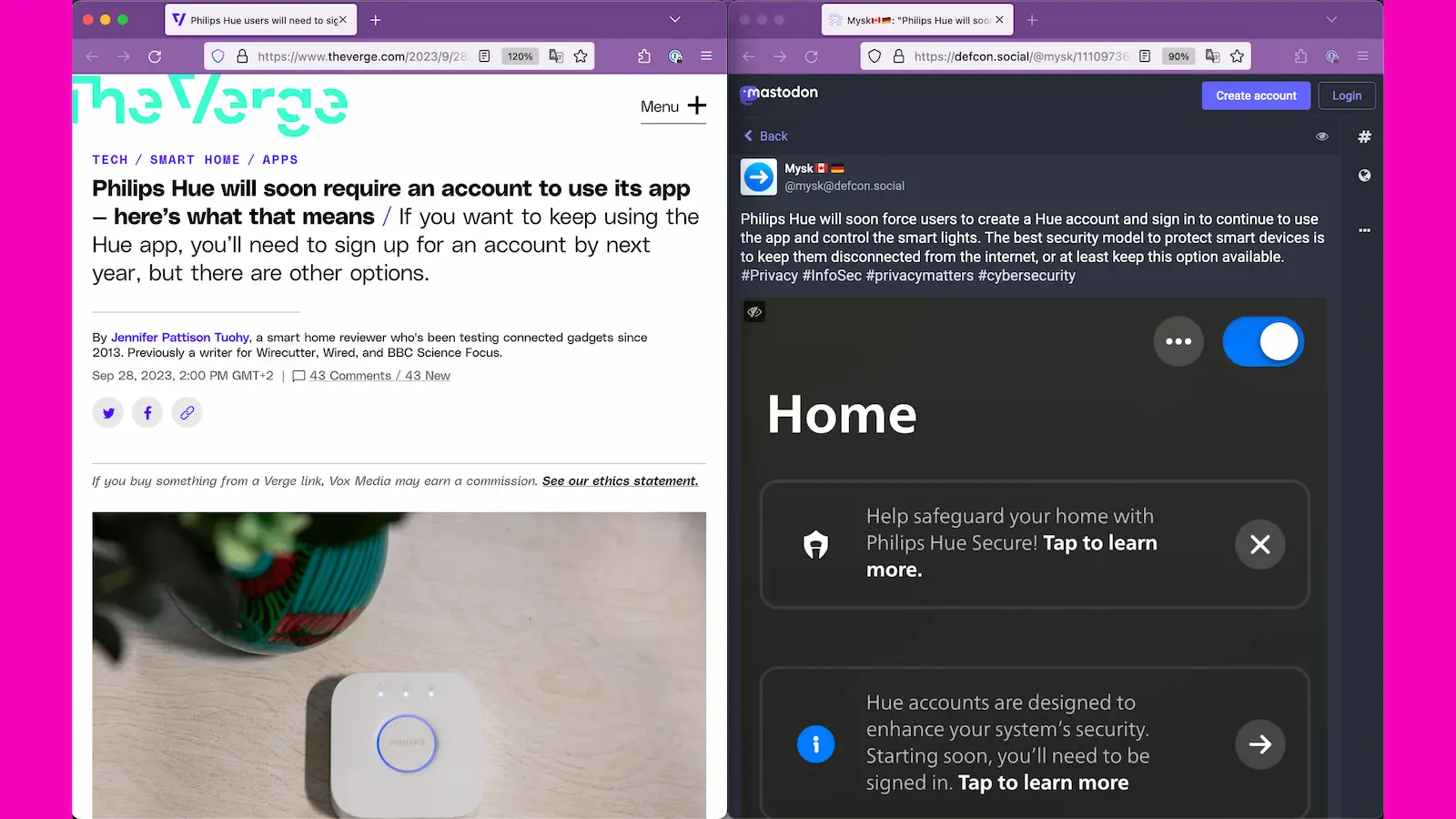
Most smart home products unnecessarily rely on a cloud architecture. Some even downgrading their products after purchase, like Hue lights.
Many smart e-bikes work exactly like Fitbit’s cloud architecture. Ask VanMoof e-bike owners.

Companies and developers seem fixated on cloud services. Why?
- The cloud web service architecture is pretty much the default choice today. It’s established and easy to get consensus to build.
- There is a ton of tooling to support building products in this way.
- It’s great for business because companies can justify a subscription from a recognizable ongoing operation cost and get recurring revenue.
- Marketers love it because they can mine customer data stored in their cloud for insights without asking for permission.

To change this, I think we need to name the alternative to the cloud architecture and describe the characteristics to help people understand the tradeoffs. We need to describe it by what it is, not just by what it is not.
Today, I am excited to share with you the leaf computing architecture.

The leaf architecture defines software that is locally executed, which means the business logic happens on a device within the user’s control and the user’s data is stored without having to trust another party.

Leaf software is autonomous. It has as little reliance as is possible and practical on external sources for capabilities.

Leaf software is federated, which means it prioritizes interoperability of capabilities and data portability across multiple providers.

Let’s go deeper into each of these aspects, starting with local execution. Local execution is about 2 things: where the code runs and where the data gets stored.
This might sound similar to another idea, offline first.
Alex Feyerke wrote about apps being offline first in 2013. He advocated for moving logic to the client-side to work offline and using client databases that were sync friendly, so they could share and receive updated state with a server when connectivity was restored. This reduces the server to only doing things the server is necessary to do, such as mirroring the data for a backup or for facilitating multi-user or real-time collaboration.
In the case of client apps, local execution has much to be inspired from offline first techniques.

But local execution is more about who controls the device where the logic and data storage happen. It’s also possible to think about local execution happening on a server that is intended to be always online and is under the control of the user.
Before Software as a Service became the norm, software companies released software that IT departments installed on their own local servers, often in the office where people worked.
Today, the best-in-class software just isn’t made available in this way and, if it were, there is not an easy and reliable way for IT teams to administer it. We have self-host-able, open source alternatives to Slack, Jira, Confluence, etc, but many of them aren’t as capable or as user friendly yet. They also require people who are Kubernetes and Linux admins to keep them running.

Why can’t we have an office server with apps that are as easy to install and update as they are on smart phones? I predict someone eventually will make the server equivalent of an iPhone and App Store. When that happens, local execution will be possible for both offline-first and online-always apps.
By the way, Nextcloud is one company trying to realize this dream. It still has a long way to go, but I’m cheering them on!

Next up: Leaf software is autonomous. Local execution and being autonomous go together quite closely.
Software is autonomous when dependencies on external services are reduced to as much as is necessary. It does not mean complete isolation. I like to think of this as cloud-assisted software. The power of the Web is, in part, our ability to build and share our unique capabilities over a network. We don’t want to lose that.
Autonomous software is further empowered by external dependencies, not powerless when those dependencies are unavailable.

Lastly, leaf computing utilizes federation.
Federation is a fancy word for playing nicely with others. It’s a spirit of cooperation between products. In software, it means sharing data formats and protocols.
When available, we opt to store data in commonly used data formats. If no such formats are available, we document and invite collaboration on the data format. We don’t want to hold user data hostage by a proprietary storage format.
Many products can interoperate simply by reading and writing data in an agreed upon format. Other times, we need to define protocols or APIs so products know how to communicate with each other because maybe it’s not data, but a capability that’s being shared.

To recap, leaf computing describes software with an architecture that is
- Locally Executed
- Autonomous
- Federated
It is appropriate for products where the user is authoritative.
It’s not appropriate for products where the user must ask for permission to do things. For example, the leaf architecture is not appropriate for an online store, where the store must manage its inventory and confirm payment.

Let’s try to apply this by redesigning a smart home air purifier from Mila. This product actually exists today, but it uses a common cloud architecture. I want to redesign it to get rid of the cloud and use the leaf architecture.
This smart home air purifier automatically senses when the indoor air quality is bad and adjusts its speed accordingly. It also has the ability to set a schedule to be a white noise generator when I’m sleeping.

I excitedly buy it. I take it out of the box and plug it in. To connect it to my home network, I push the Wi-Fi Protected Setup or WPS button on my router and it magically joins. WPS eliminates the complicated pairing process or remembering your Wi-Fi password.

A smart air purifier is basically a dumb air purifier with a web server serving a progressive web app and APIs.
It uses zero-configuration networking (also known as zeroconf or Apple Bonjour) to make itself easily discoverable on the home network.
The screen on the air filter tells me to go to air-filter.local on my phone’s browser.
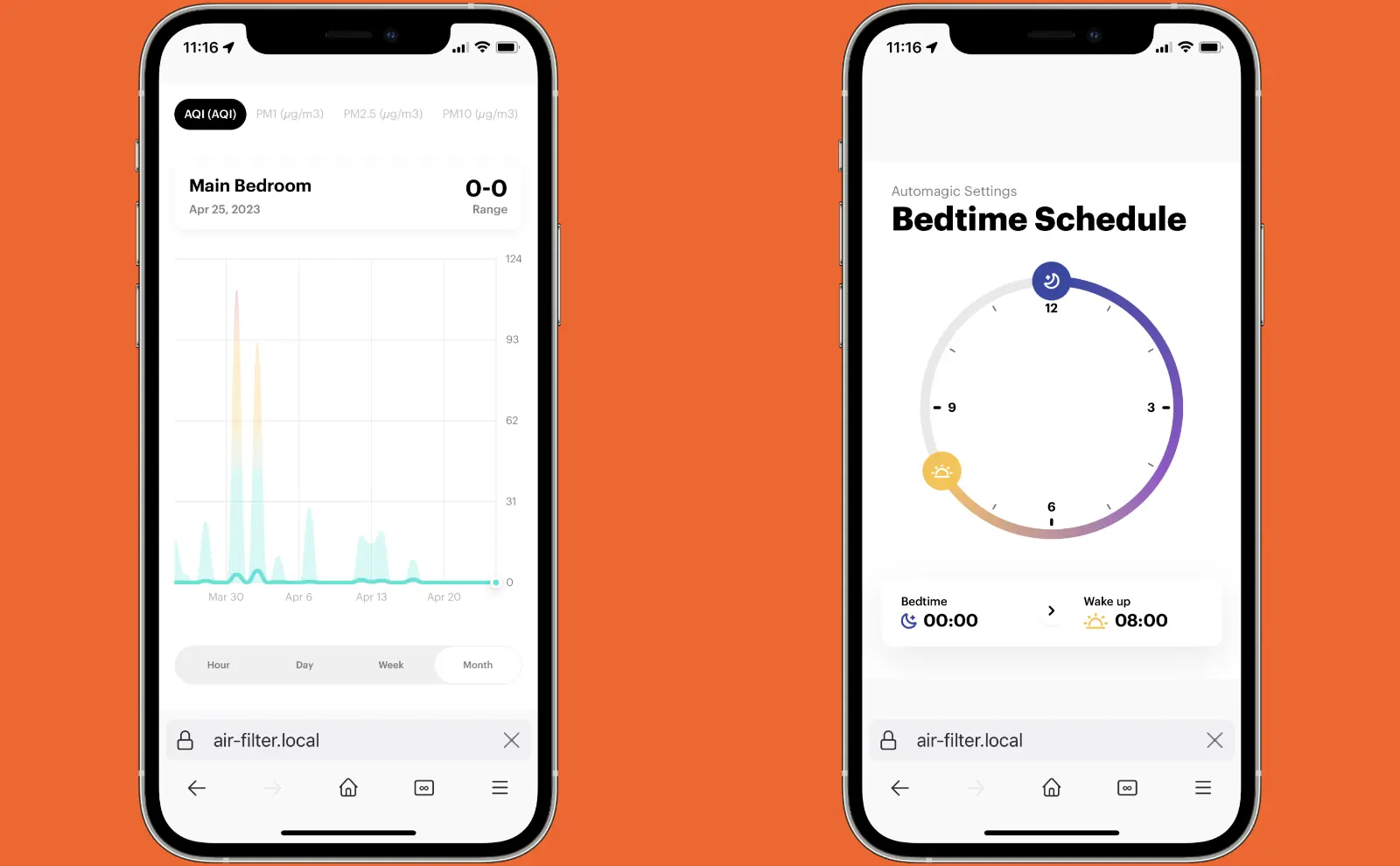
I see a Web app that shows me the history of the air quality. It also has the setting for scheduling the white noise mode for when I’m sleeping.
The configuration data and the historical air quality data is stored only on the air purifier itself.

But what if I want to be able to control it when I’m not on my local network. Let’s say I go on vacation and forgot to turn it off. I don’t want it to use electricity while I’m away because it’s expensive these days.
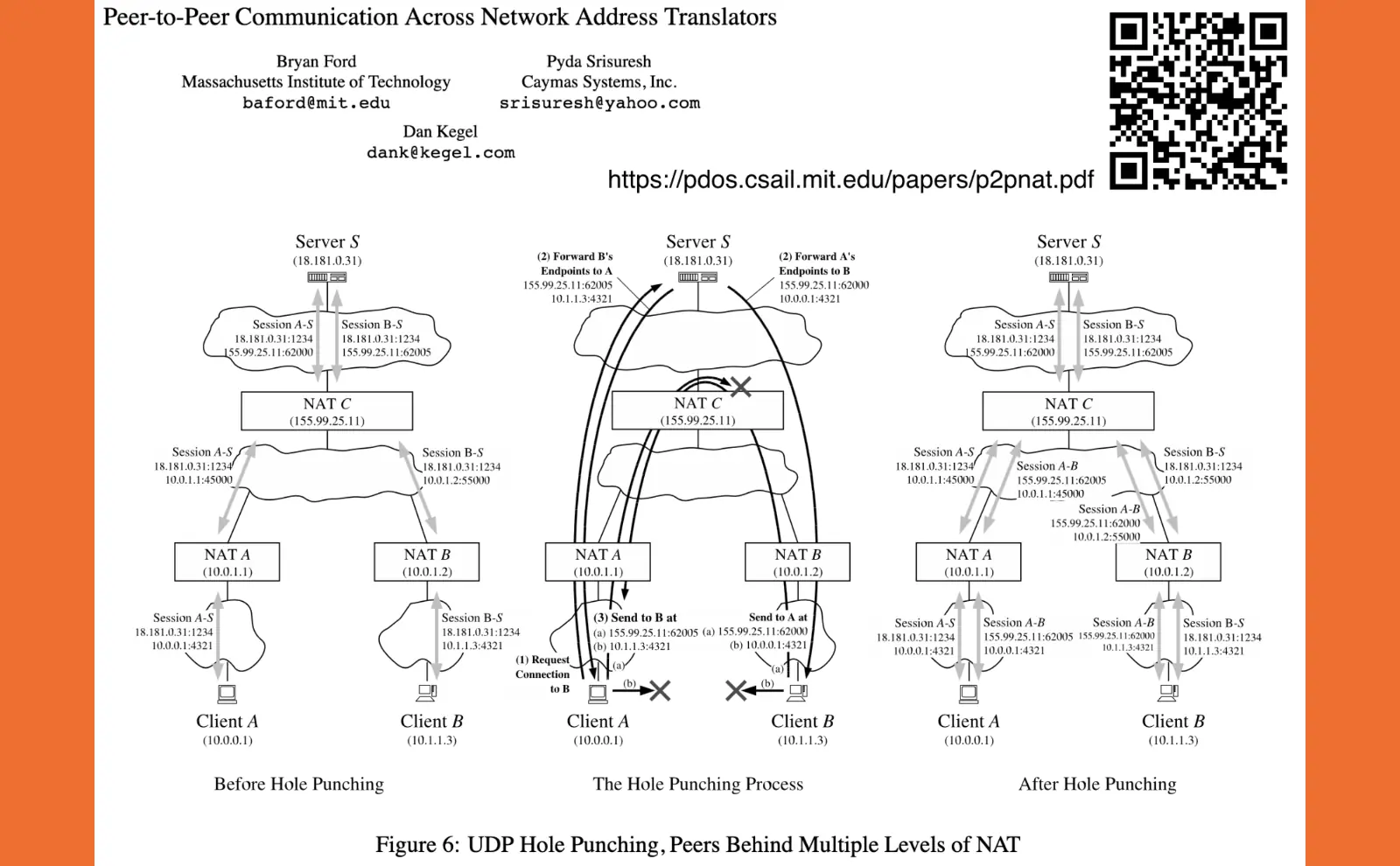
The challenge is that I can’t connect to a device inside my home from the outside easily because of network address translation and opening ports on my router is complicated.
The typical way smart home device manufactures deal with this is to move all the control logic and configuration data back into the cloud, but we want to keep the air purifier as autonomous as possible.

Fortunately, we have a standard called WebRTC that allows for peer-to-peer data connections. It’s what is used in many video chat apps today.
I’m not going to get into the details of the sequence diagram for how this works. The important detail is that it allows for 2 parties on separate, private networks to establish a peer-to-peer connection with only a cloud assist to get it started.

The air purifier company hosts a website for this cloud assist. My smart air purifier connects to this website and shows me another link on its screen that I can go to on my phone. I bookmark it or save it to my home screen.
When I go to this website on my phone, the website facilitates a peer-to-peer connection to my smart home air purifier using WebRTC. The air purifier then serves its progressive Web app and data to my phone just like it would if I were at home on my local network. The cloud server does nothing else. The app on my phone and the air purifier are talking directly to each other once initially connected.
But now, what if I want to get a notification when the air filter needs changing? No problem! The smart air purifier is serving a progressive Web app, which can use the Web Push API to send notifications, just like a cloud-hosted and native mobile app would.

But now, what if the smart air purifier company wanted to use machine learning to detect when mold is more likely to grow due to high humidity and preemptively filter the air more before the mold can start to grow and become a problem?
The company could use something like TensorFlow.js to run machine learning models directly on the smart air purifier itself.
Again, we’ll use a cloud assist to get the current weather forecast data from some API provider and mash it up with the air purifier’s own sensors and run that machine learning model to predict and protect against mold.
Superface is a neat product that allows you to do a single API integration and flip between providers as desired, enabling federation even when the providers refuse to agree to a common protocol.

Ok, but now the air purifier marketing folks want to know more about how customers use the smart air purifier out in the real world. Is there any way we can get telemetry data without invading people’s privacy? Yes, there is.
Some smart researchers at Stanford University came up with Prio, a privacy-preserving system for the collection of aggregate statistics.
Mozilla has been using in Firefox since 2018. (source) It enables learning about how users use the product without being able to identify individual users, so their privacy is protected.
Of course, the air filter does ask for permission to participate in aggregated statistic collection first. I agree because I know that products get better with data-informed decisions.

We now have a rearchitected smart home air purifier that:
Uses locally executed software to serve a progressive Web app, store configuration data, and run local machine learning models.
Is autonomous, operating without the cloud when on a private home network, minimally without cloud on the public Internet, and only using weather APIs for real time data it otherwise couldn't have itself
Benefits from federation. It can choose amongst a variety of weather data API providers for advanced functionality. It’s not locked into a single vendor.
I know it’s a simplified example. A real world use case would need to account for the device being put directly on the public Internet for some reason, use on routers without Wi-Fi Protected Setup, multiple smart air purifiers on the same network, and defensively securing the device. My hope is that you got an idea of how to start applying the leaf computing architecture.

By creating software that is locally executed, autonomous, and federated, we get products that are more secure, more resilient, and not at risk of becoming e-waste prematurely.
The leaf computing architecture benefits the user while reducing security risk liability and operational costs for the manufacturer. What’s great for the environment is also great for the wallet because you aren’t paying for as many server resources.
I hope you join me in creating technology products with these ideas. The future will be bright and sunny when it’s a lot less cloudy.
More information can be found at LeafComputing.net.