JSON API: Your smart default
• Updated
This is an adaptation of my presentation at the Nordic APIs 2017 API Platform Summit in Stockholm, Sweden on October 10, 2017. I updated it for APIDays Paris on January 30, 2018 and expanded it for API Conference London on April 11, 2018 and WeAreDevelopers World Congress in Vienna, Austria on May 16, 2018.

Hello, I’m Jeremiah Lee. I am going to be talking about my experience at Fitbit, where I led its Web API for 4 years.

This is a talk about JSON API a.k.a. the JSONAPI.org specification, but I am not going to read the specification to you or lead a tutorial on how to use it. If you are unfamiliar with spec, that’s ok! Please stay for my talk. I hope that my talk convinces you to read more about it later today. Because ultimately, I hope to convince you that the JSONAPI.org specification should be your default style when designing Web APIs. It won't be best for every situation, but it is a great default starting point.
I’m going to talk about the Web API problems Fitbit had and how and why the JSONAPI.org specification’s features helped. I have consulted with many companies on their Web API designs and I have seen common patterns emerge. While I am using Fitbit as an example, I suspect its problems will feel familiar to you.

Before I get started, I need to make a disclaimer: some of this information is aspirational. I helped get this going at Fitbit, but I do not know the current state. In April, I moved to Sweden for my husband’s work. As far as I know, none of Fitbit’s JSON API-based endpoints have been released on its public API. The views represented here are my own and have not been reviewed by Fitbit.

For those of you who aren’t familiar with Fitbit, it is a digital health and wellness company. Fitbit pioneered the activity tracker and wearables space. Fitbit released a public Web API before most of its competitors even existed. Today, the Fitbit Web API is used by thousands of apps, hundreds of which are meaningfully activated by people. As of last November, the Fitbit Web API served at least 4 billion requests a day with about a quarter from third-party apps. Fitbit can attribute tens of millions of dollars in annual revenue to sales driven by partners using its Web API.
Fitbit's own apps use the same Web API that is available publicly. I am going to focus today on the problems the teams building these apps had.

The first problem: client teams had very different perspectives on how they wanted to retrieve information from the server.
Fitbit had 4 major clients, the Fitbit app on four platforms: Android, iOS, Windows, and Web.
Fitbit organized teams into full stack feature teams. This was a team composed of a product manager, program mananger, designer, QA engineer, engineers for each client, backend engineers. They were responsible for an entire feature area, such as exercise logging. They had everyone they needed to release a feature in the Fitbit app on every platform.
New features were implemented on one platform first to prototype. The platform typically was chosen based on engineering availability. Once the experience had been finalized, other client engineers “fast followed” in implementation on their platforms.
This could have worked, but Android and iOS developers had very different ideas of what an ideal Web API would look like. The iOS developers preferred fewer network requests and were ok with the performance of parsing large API responses. Android developers, however, preferred smaller API responses and accepted the tradeoff of more network requests. There was no way to reconcile this with the version 1 Web API. The two biggest client teams wanted the exact opposite of each other because they had different primary constraints.

The second problem: without clear guidance, the data models got messy. Because of the large amount of data available, API endpoints started to resemble view-models instead of well-defined, normalized data models. Teams regularly overloaded existing endpoints in order to not make clients make another API request. Endpoints were filled with loosely related data instead of being well-scoped. Often, data would only be split across multiple endpoints when there was a new distinct view in the app when another request could be justified to the client developers. This could be fine, except the experience evolved over time. What data was needed for a view changed, so the data seemed arbitrarily split. There was no librarian.

Third problem: misalignment between client and server data models. Clients didn’t think about data in the same way as the server. This wasn't their fault. The server's classes and underlying database models were not considerate interfaces. This problem was complicated further because Fitbit has a multiple ways data can be expressed: summaries, collections of logs, and time series.
The problem was not limited to client—server data models. Even though the Fitbit app had a mostly consistent end-user experience across four platforms, each platform's client team created their own internal data models. Client developers picked different expressions of the data from the Web API and plucked the relevant data from the API response to suit their particular platform's internal data model.

Fourth problem: Clients had great difficulty staying in sync with the server. Fitbit devices synced data every 15 minutes, but data could change more frequently. Many people used the Fitbit app on multiple platforms. A change made from the Web app on their laptop should show on their iPhone quickly. Many people also used third-party apps that could modify data and those changes from the server needed to be reflected in the app. The Fitbit apps could also be used offline and would need to reconcile changes made offline with new changes from the server when reconnected.

Again, here were the top 4 problems that clients had with the Fitbit Web API.
How might we solve these particular problems? What would be the requirements be?
- We would need to settle the debate over number of requests versus request size.
- We would need an agreement on data models and how the data fits together.
- We would need an agreement on how to handle data between the client and server. We would need a common approach to selectively retrieving parts of data and related data.
- We would need the ability to check if data has changed with as little overhead as possible.

Let’s take the first one. The hypermedia proponents burned much credibility by fetishizing REST instead of focusing on problems client developers actually had. This made my discussions about Web API design styles difficult with client developers at Fitbit.
When suboptimal networks have a significant impact on perceived and actual client performance, it is reasonable for clients to want to minimize interactions over the network. Too many Web APIs have been designed with the assumption that the clients are high end servers with perfect network connections. That’s just not the world that mobile clients live in. And in Fitbit’s case, the vast majority of Web API requests were made by smart phones on hostile cellular data networks.
When tensions are high, we need to bring data to an argument.

We agreed that betting on the future was a reasonable thing to do. We agreed that network performance was something getting better at a reasonable enough pace that making short term tradeoffs in order to take advantage of new advancements as soon as they became available on the server and client platforms would be acceptable.
We agreed to three hypotheses to test:
- HTTP/2 would meaningfully reduce the overhead of multiple requests. Specifically, we were looking for binary and compressed headers with HPACK to significantly reduced the overhead of multiple API requests. Also, we hoped pipelining would make handling of multiple, concurrent requests easier on the client because they wouldn’t need to manage network connection pooling.
- TLS 1.3 would meaningfully reduce latency introduced by HTTPS. It reduces the initial handshake in half from 2 to 1 round trip. Once that happens, preshared key session resumption and zero-round trip resumption would make subsequent secure connections significantly faster to establish if the connection were interrupted. This would be a noticeable win for reducing latency for end users far away from Fitbit’s Texas datacenters.
- LTE network coverage would expand. LTE is not only a faster connection, but also a more resilient connection from its switch from a switch-based to a packet-based network.

We tested these assumptions. I wish I could share the data from them, but you can find more rigorous tests that prove this better than what we did. The important part is that this allowed us to come to an agreement that small resources and lots of HTTP requests can be ok.
This was especially true on fragile network connections. If the responses were small, the hit for retrying a request was lower and the faster the response completed, the less exposure the response had to being interrupted and having to restart all over.

Once we removed the fear of small requests, we could work on an agreement to define a common data model for resources. We set out to try to normalize data, just like we might in a database. We still accepted that there could be multiple expressions of the data (e.g. time series, summaries, logs), but that the data should be canonical and should not be repeated across endpoints.
We immediately realized the need to define relationships—or if you prefer buzzwords, “a graph”. In this case, a graph is just identifying a relationship between data and naming that relationship. This is the first time I’m going to bring up JSONAPI.org specification. It sets explicit expectations about how to define and name relationships between data.

Here is how one of its creators, Yehuda Katz, described JSON API:
JSON API is a wire protocol for incrementally fetching and updating a graph over HTTP
JSON API is a wire protocol, which means it includes both a format for resources and a specification of operations that you can do on those resources.
JSON API works incrementally, which means clients can fetch data as they need it at the appropriate granularity.
JSON API defines a way for both fetching and updating because modifying resources often is just as important as fetching them.
JSON API defines a graph structure, which enables data to be linked together in a well-defined way.
JSON API works over HTTP, which means JSON API uses the HTTP protocol—including its caching semantics—as its backbone.

Here is a hypothetical response for a social feed post. Most of the content is in attributes.

There are also relationships defined, such as for the user profile data. After fetching the newsfeed posts, the client could then fetch the user information, since it’s a distinct type of data.
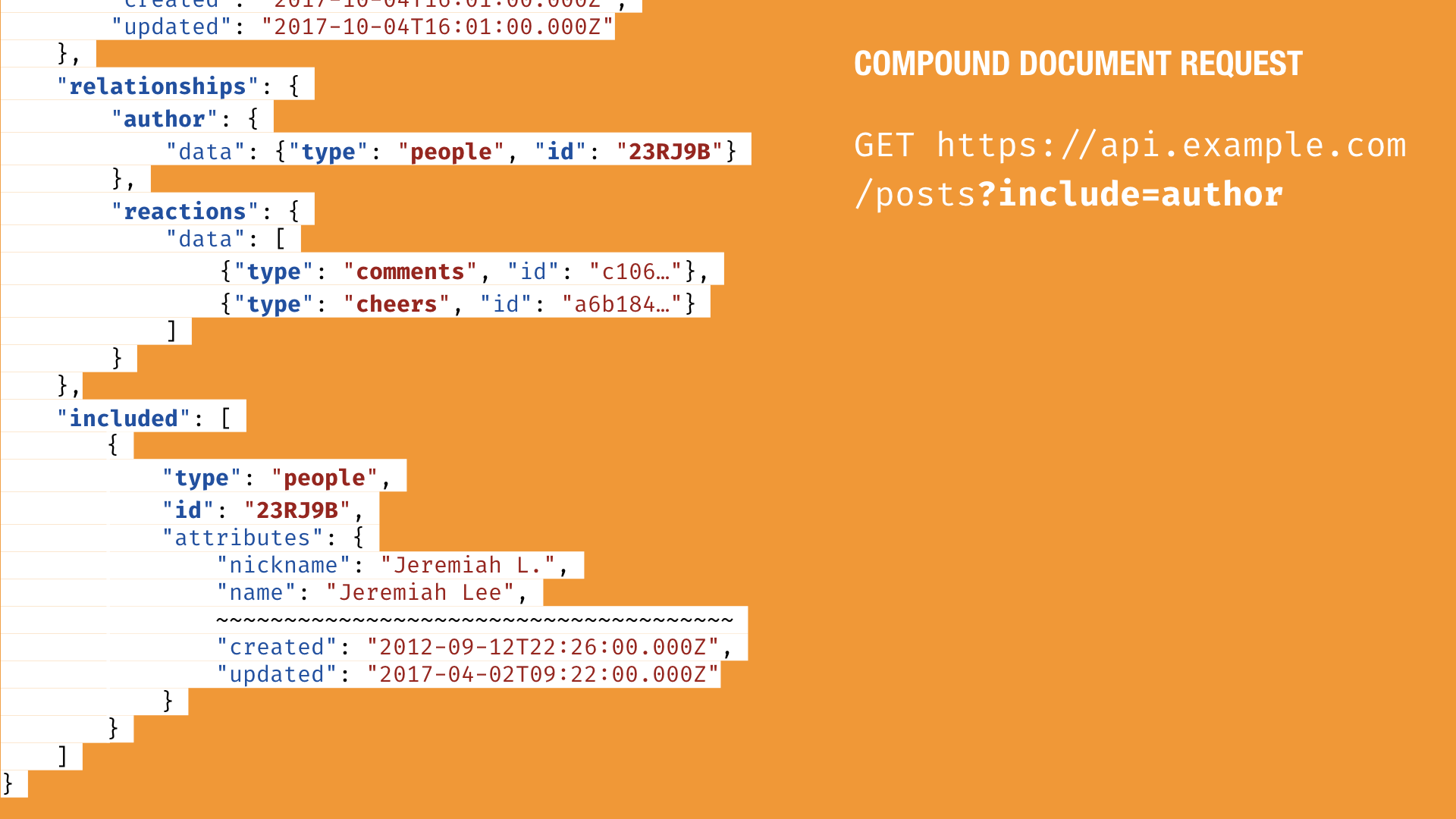
Going back to the client use case, it is reasonable to assume there will be situations where clients will need a resource and its related resources at the same time. While a client could get the initial resource with its defined relationships and then go fetch the linked resources, that puts a lot of work on the client to get a response, parse it, get the relationship URL, request it, and potentially do this multiple times.
The JSONAPI.org specification has a way of dealing with this use case. It’s called compound documents. It allows the client to include specific resources in the initial resource request to avoid chaining multiple requests together. It works simply by adding the include URI parameter for the relationship.

But then we’re back to the problem of potentially large API responses. In the case of an exercise summary, there is a lot of data that could potentially be requested just in the summary. Once again, JSON API provides a solution for this problem.

It’s called sparse fieldsets. It is a standardized method for allowing clients to specify only the properties they want from an object returned in the response. You add a `fields` URI parameter with the resource type and the field names you want.

Sparse fieldsets also work when requesting a compound document. Simply include the relationship and add its resource type and fields desired.

One of the benefits of the JSONAPI.org specification is how optional it is to the client. Its default behavior is pretty much the same as any plain ol’ JSON REST-like Web API. Hopefully it’s a bit more intentionally designed with its data objects and relationships, but none of the features have to be used by clients. They’re optional and ready to provide optimizations for clients as soon as clients want them.
One of the challenges at Fitbit was not just getting clients to agree to common data models, but getting them to agree on a common way of retrieving, storing, and presenting data. This part is not related to the JSONAPI.org spec, but I think it’s important—it is how a client can leverage the features within the API to improve the perceived and actual performance of the end-user experience.
Here is data lifecycle for how clients might choose to implement.
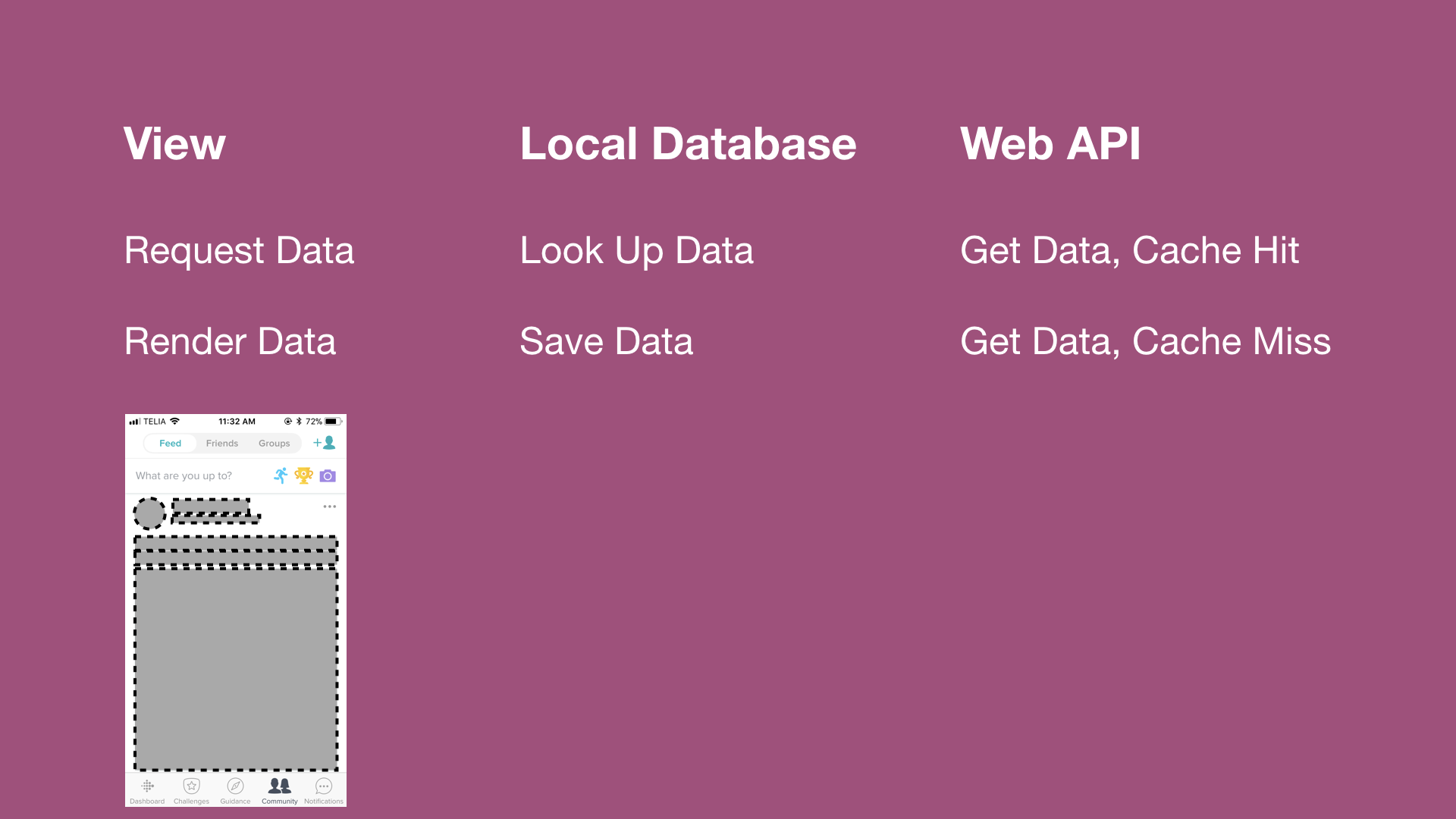
The first example is for fresh data. The view is going to request the data from the client local database. The database won’t have it, so it’s going to fetch it from the Web API. It will be a cache miss because it hasn’t retrieved it before. The database will save the response from the server, which will cause the view to render.
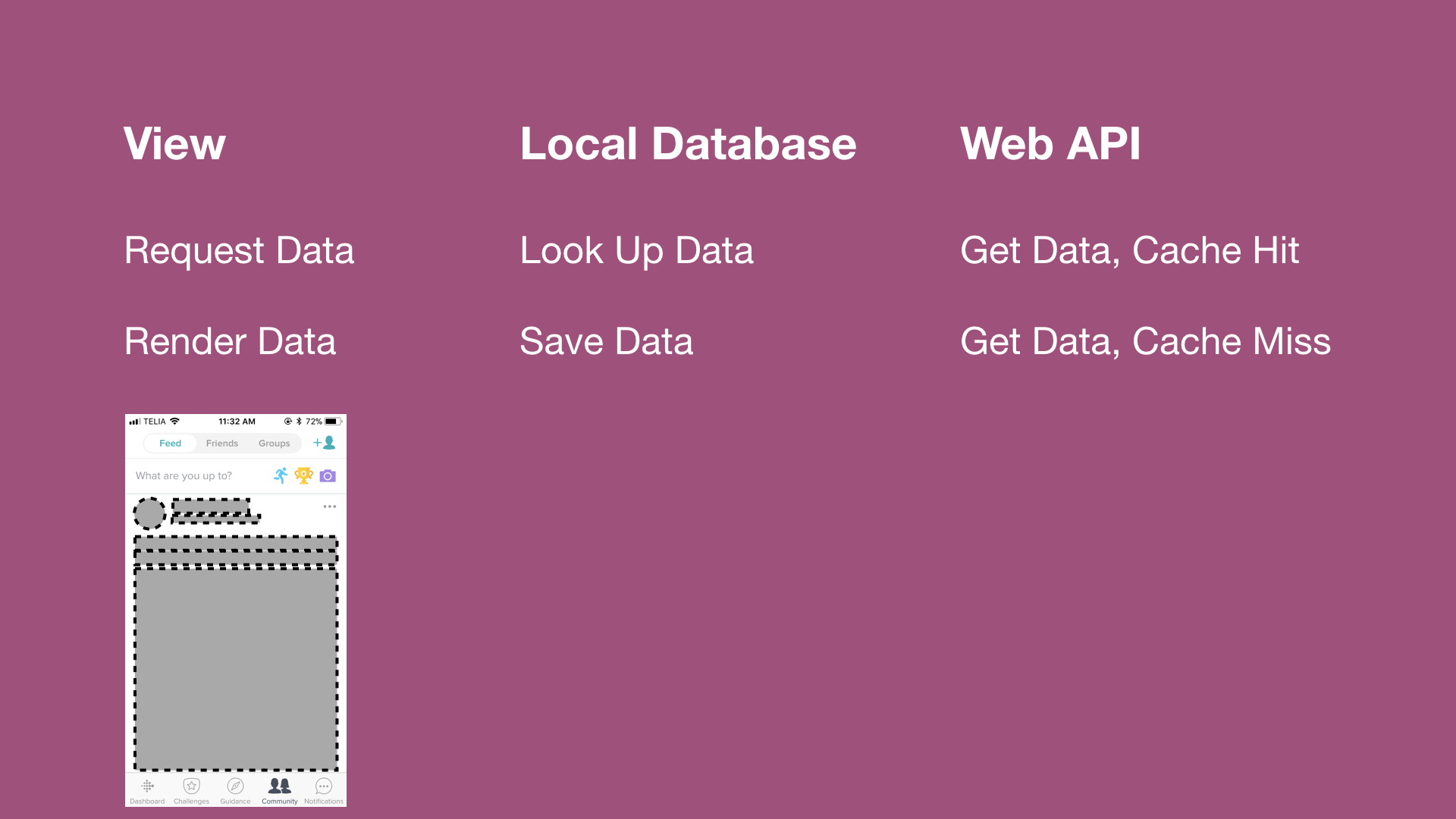
The second example is for previously retrieved, unchanged data. If that data already existed in the database, the database would return the data and simultaneously ask the Web API if the data has changed. If the data hasn’t changed, nothing else happens.
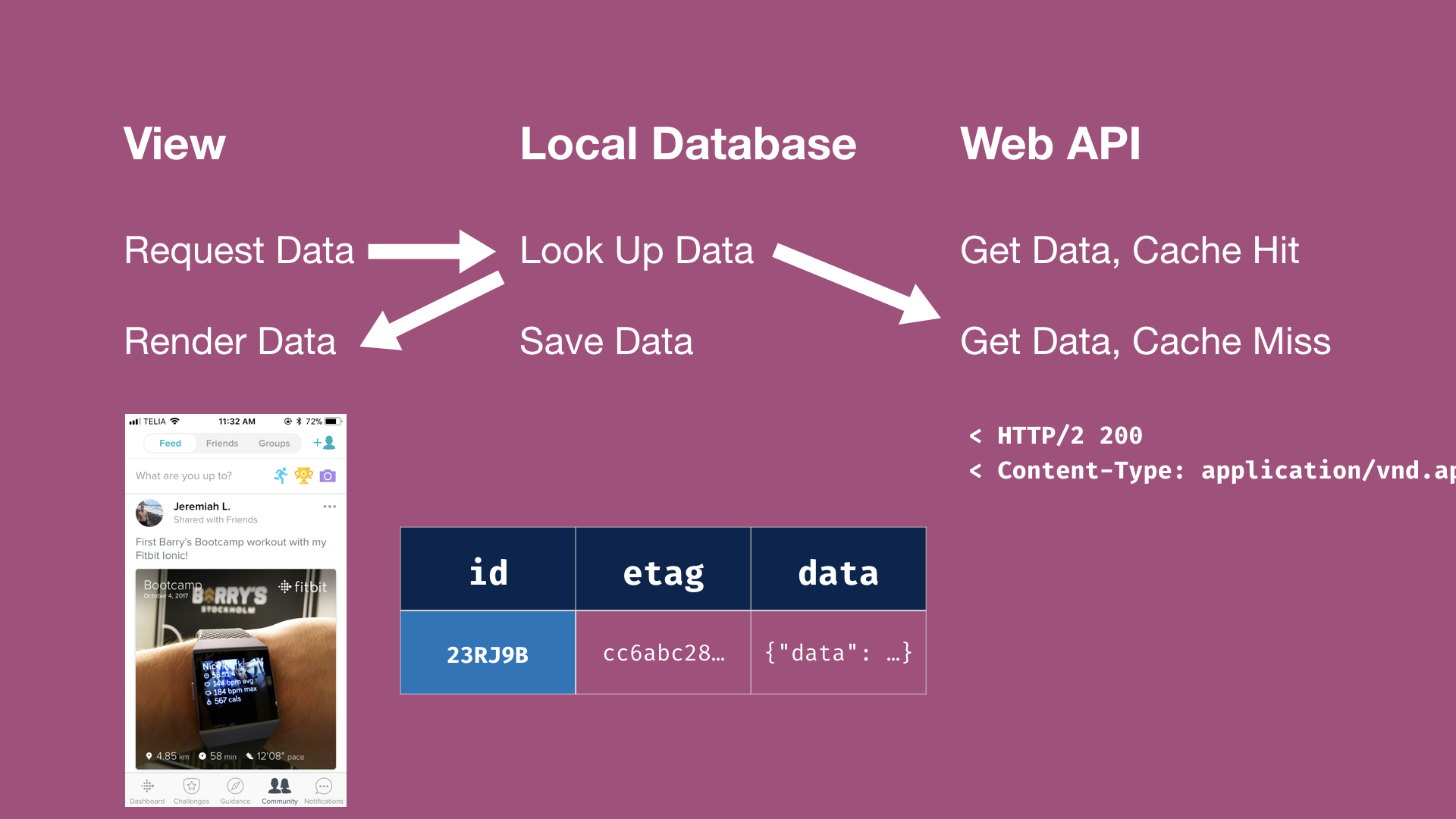
The third example is for previously retrieved, stale data. As soon as the the header response returns a 200 OK HTTP status header instead of a 304 Not Modified, the view can be triggered to display an updating state. When the body of the Web API response is received, it is stored in the database, and the view is updated with the latest information.
A key detail is that the data model is mostly shared between the client and the API. It’s key-value driven, with collections based on the data type, with the relationships and meta data stored. Clients also have flags to know if data is only partially represented (i.e. sparse fieldsets were used) or not yet synced if being updated from the client. This allows apps to more easily stay in sync with the server and to operate reasonably well offline.
This resolves problem three, which leads me to the requirement of caching.

Well-scoped, normalized resources have an additional benefit: they improve cacheability. If data changes affect fewer resources, then there will be fewer resources invalidated when data changes. Because all of the clients now are accessing data in the same way, we don’t need to put the same data in multiple places.
Caching is a feature that is built into HTTP and JSON API leverages this functionality, but it does require a minor shift in thinking.
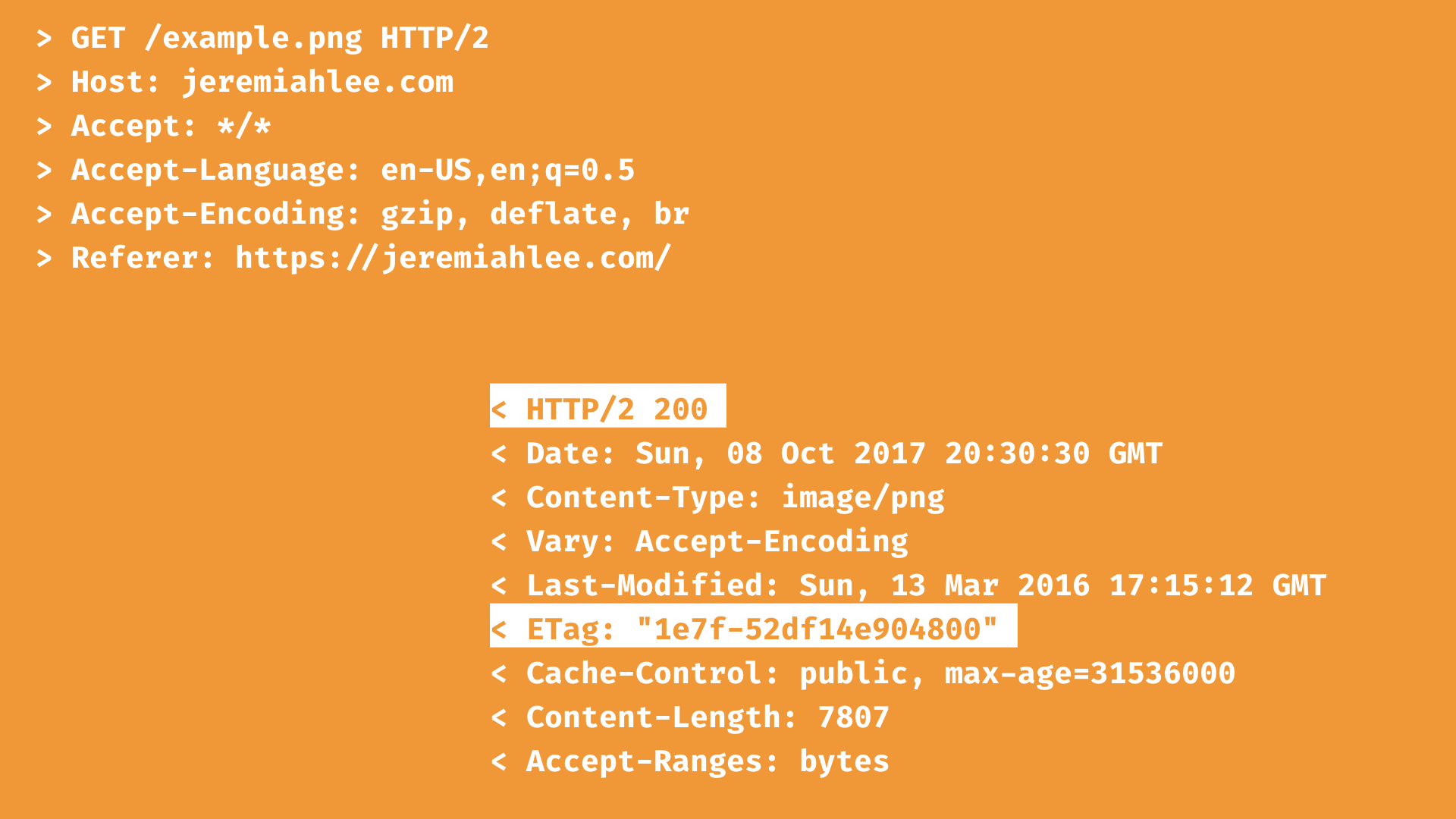
This is an example of fetching an image from a server. When the resource is returned for the first time, there is an ETag header sent with it.
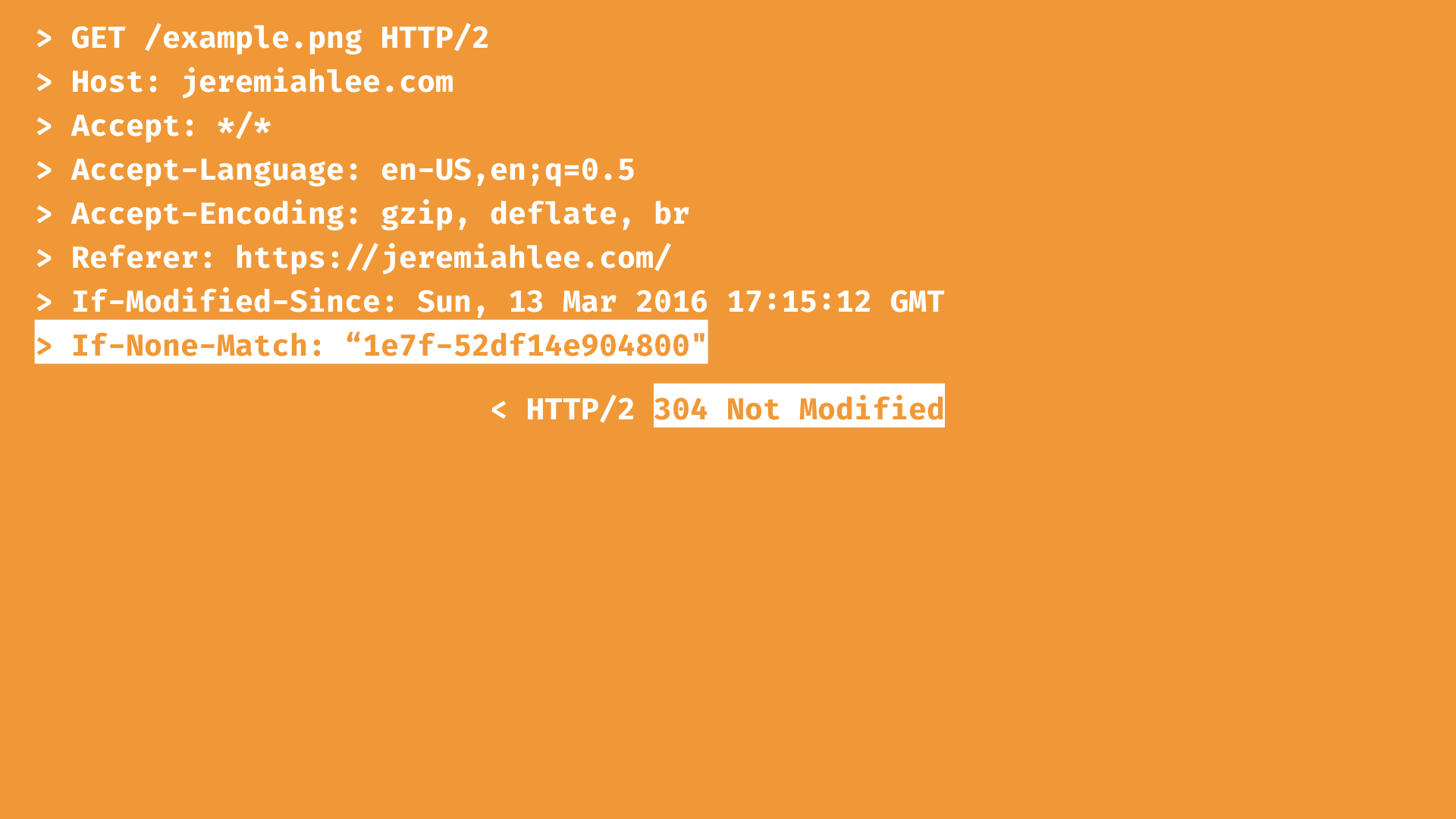
When the client requests the image from the server again, it send the previously returned ETag in the request. This allows the server to respond with 304 Not Modified if the image hasn't changed and the client can load the image from its cache.
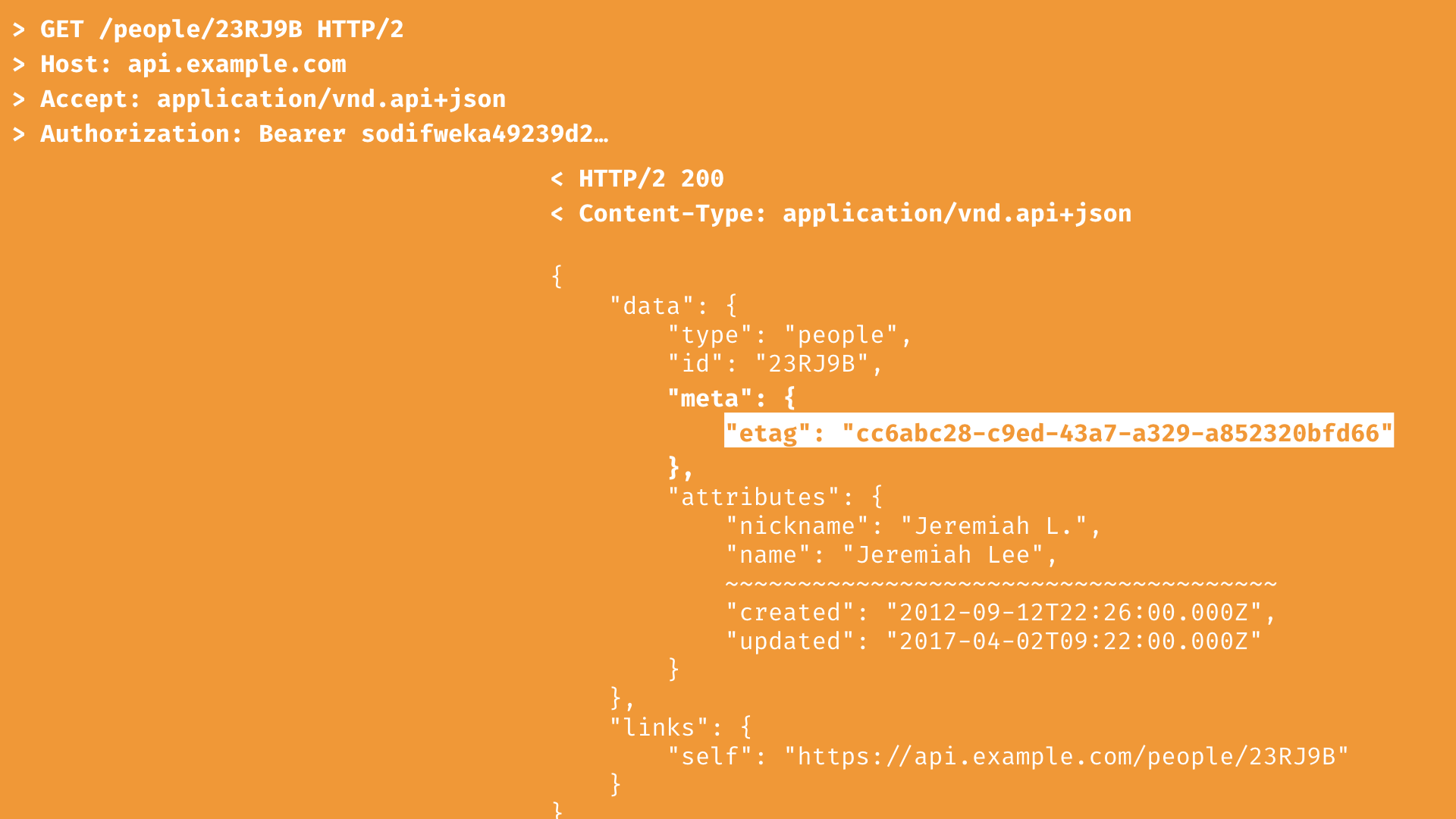
But with a JSON API response, the ETag is not returned in the header. This information is in the meta object. The ETag for a JSON API response cannot represent the exact bytes of the response because a request might have used JSON API features like sparse fieldsets or compound documents. Instead, the ETag in the meta object represents the version of ever resource and relationship returned in the response.

The ETag is still passed in the If-None-Match header on subsequent requests. You still get a 304 Not Modified response if the version or state of the resource has not changed.
Let’s put it all together. What does this look like in practice? The Fitbit news feed is a great example of data with mixed caching scenarios.
Most of the data is news feed stories, which is a mostly ephemeral experience. People are unlikely to see the exact same content more than once because new content is always being created. The stories are unlikely to be cached. However, the stories have related content that is likely to be cached and repeatedly accessed: the story creators, i.e. your friends.
If there are 20 news feed stories by 15 friends, that would mean that the client can save downloading up to 5 friends’ basic profile data multiple times. And if the user had viewed their friend leaderboard prior loading the news feed, the app would not need to re-download any of their friends’ basic profile data. This is a nice performance benefit from having normalized data with defined relationships. It adds up across the multiple experiences within the app!

You might be thinking, why didn’t you just use GraphQL? Well…
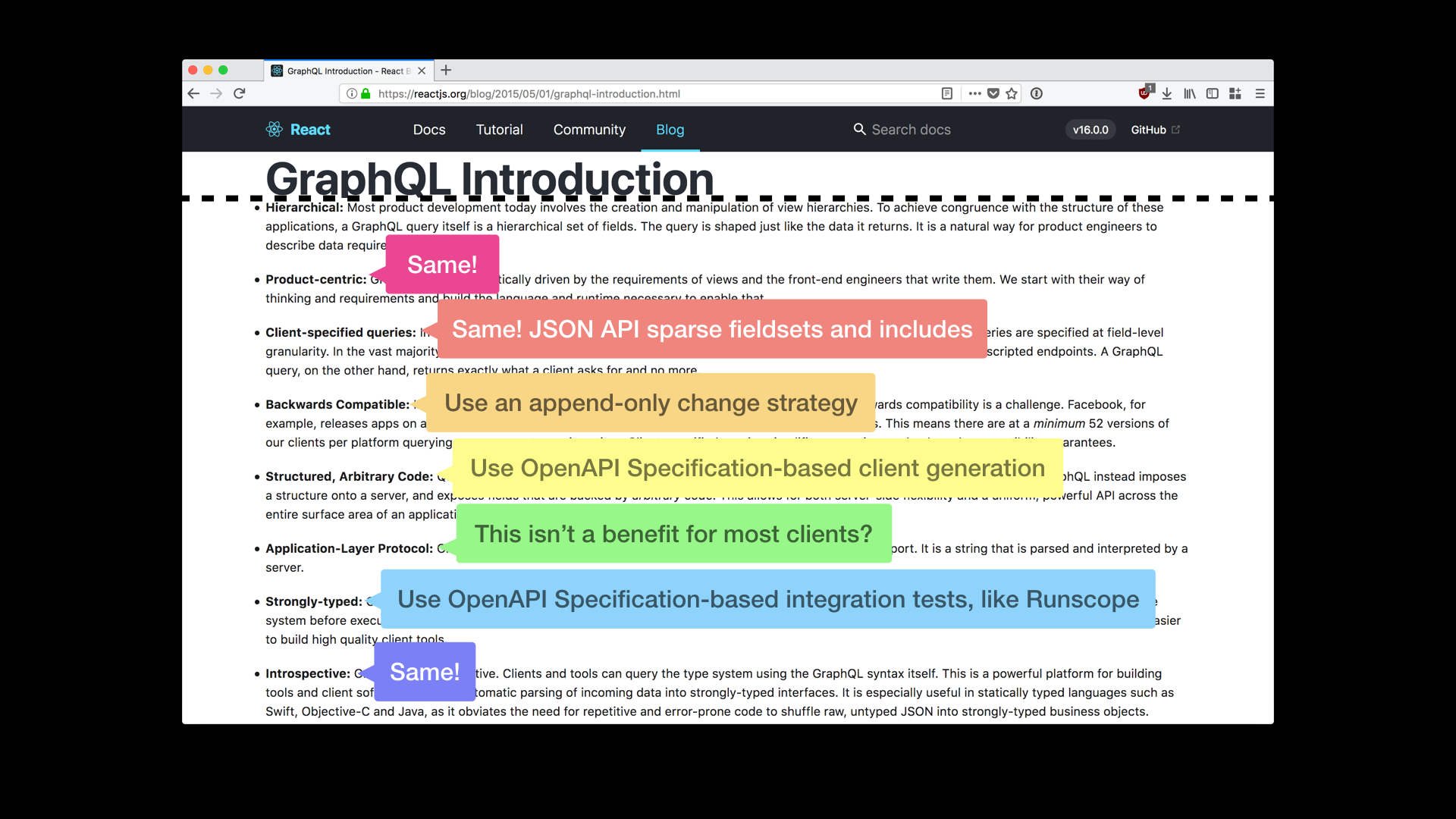
GraphQL features can be obtained with the JSONAPI.org spec without requiring developers embrace another tool chain. Sparse fieldsets and compound documents provide the main performance benefits people like in GraphQL.
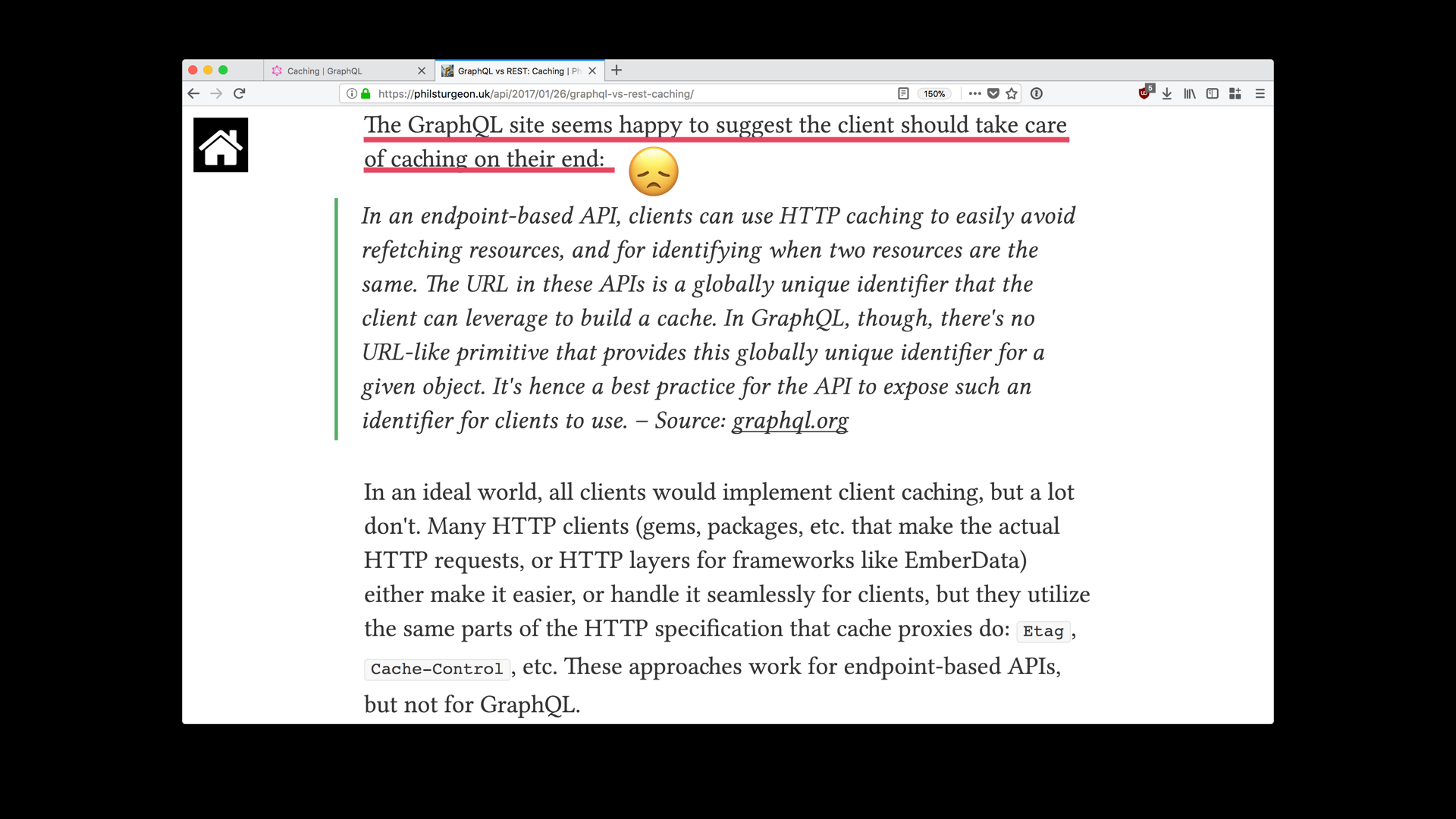
But unlike JSON API, GraphQL does not leverage the built in caching features of HTTP and does not have a suggested common approach to caching. If a client developer works with multiple GraphQL-based APIs, they will likely need to learn and accomodate multiple caching methods. More so, an effective caching mechanism is difficult to implement when clients compose the response from multiple server data sources. I believe that caching is too important of a client performance consideration to be an afterthought.
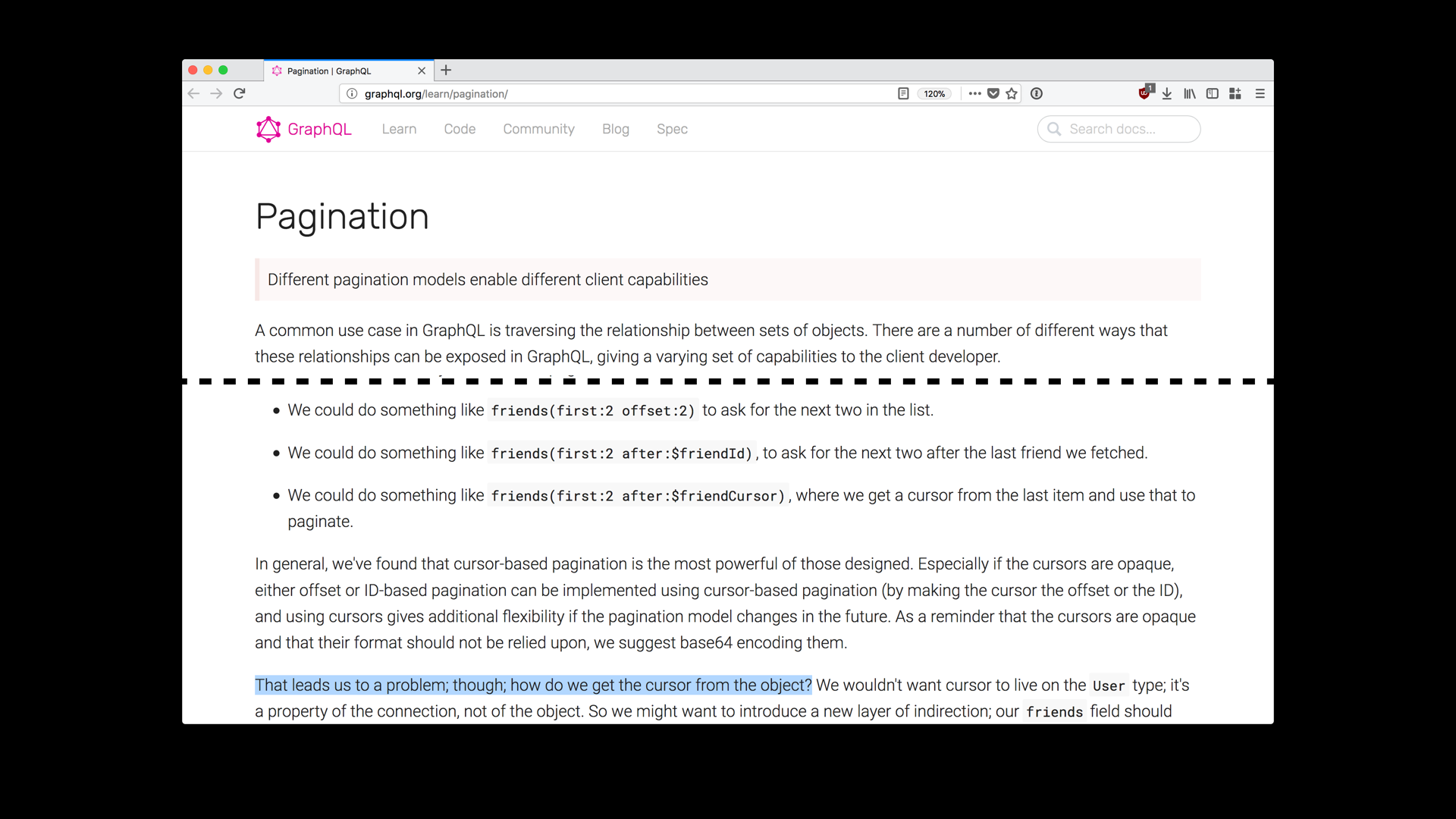
Another common use case not addressed by GraphQL is pagination. I didn’t talk about collection access with JSON API today, but pagination is part of it. next and previous links are provided to clients and clients simply request them. This enables the a JSON API-based server to specify a pagination strategy, as this is one of the areas where the database implementation details are difficult to hide.
Pagination in GraphQL is done by the client. This is unfortunate, because it makes it very easy for clients to make very expensive database queries. For example, when paginating with offset, many databases still needs to process all of the query results first and then apply the offset by only returning a portion of the computed results to the client. As the offset grows, the amount of processing on the server grows. I won’t get into a details about cursor strategies for pagination, but I do believe this should not be something clients should have to worry about. Again, I think the pagination use case is too important and too common to be an afterthought.

Lastly, I believe there is an inherent advantage to clients and servers sharing a common data interface as much as possible. Reflective input/output makes composing create and update statements from the client much easier when the data model is shared. It also enables using JSON Patch for incremental updates.

In conclusion, I hope that I’ve convinced you to consider JSON API for your next Web API. While I think GraphQL is an advancement in API design, I think the JSONAPI.org specification addresses the concerns of client developers better.

I hope that I’ve convinced you that making suboptimal networks less painful for client developers is something API design styles can help with.

I hope that I’ve convinced you that designing data models with intent and study of client needs is not a step that can be skipped. Both GraphQL and JSON API give clients control over what data is returned in the API response, but that does not mean highly intentional API design does not need to happen.

So that’s all for now. There are a few other features that I didn’t have time to cover in this talk. There also is great tooling available for every major app platform and framework—if they want it. The best part is that clients can use a JSON API-based API without needing them.
Please go check out JSON API. Don’t hesitate to reach out on Twitter if you have questions or create something cool with it.
Photo credits
- “Construction site and caution” by Matthew Hamilton,
- “Tree, forest, question and bark” by Evan Dennis
- “Green cat eyes photo” by Paul
- “Begin Here” by Tyler Lastovich
Compatibility notes
This post contains animations in the APNG format.
This post contains a video in MPEG-4 H.264. I hope one day we will have a patent-unincumbereduniversally supported FOSS option instead.